Posts
Behavioral Cloning Breaks in Predictable Ways (and What Helps)
.
Behavioral cloning can look strong in one-step metrics but fail in closed-loop rollouts due to compounding error. In multi-modal settings, MSE often averages valid expert behaviors into invalid trajectories. Action chunking and larger models can help stability and representation, but they do not solve distribution shift on their own.
February 2026.
Coding Generalist Robotics Policies from Scratch
Glen Berseth.
In this tutorial and code, I share and walk through the process of building a mini generalist robotics policy. Starting from Karpthy’s mini GPT code, we create a vision transformer, and from the vision transformer, we create a generalist robotics policy, which is a type of multi-modal model. The final model is based on the paper "Octo An Open-Source Generalist Robot Policy" which is a great paper that includes open-source code.
October 2024.
Open PostDoc Position in Machine Learning
Glen Berseth.
Looking to shape the future of machine learning? Interested in doing research in a stimulating, collaborative academic environment? We ([Glen Berseth](http://www.fracturedplane.com/) and [Yoshua Bengio](https://yoshuabengio.org/)) are hiring a postdoctoral researcher to collaborate across our labs. This position will be at Mila, the world-renowned AI hub located in Montreal, Canada—home to over 1,000 people pushing the boundaries of AI research. For this call, we are prioritizing candidates with experience in reinforcement learning, scientific discovery, or high-impact applications of ML. However, candidates who overlap in related areas are encouraged to apply.
July 2024.
DROID A Large-Scale In-the-Wild Robot Manipulation Dataset
Glen Berseth.
The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350h of interaction data, collected across 564 scenes and 86 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance, greater robustness, and improved generalization ability. We open source the full dataset, code for policy training, and a detailed guide for reproducing our robot hardware setup.
February 2024.
Graduate Applications Tips for Computer Science Students
Glen Berseth.
Your application is made up of many parts, and each part serves a purpose and speaks to a different audience. Keep in mind the readers of these applications want to be confident you have the knowledge and passion to succeed at graduate school.
September 2023.
Montreal Robotics Summer School (2023)
Glen Berseth.
 |  |  |
| School Photo | Getting excited | This years champions |
Robotics is a rapidly growing field with interest from around the world. This summer school offers tutorials and lectures on state-of-the-art machine learning methods for training the next generation of learning robots. This summer school is an extension supported by the many robotics groups around Montreal.
June 2023.
Towards Learning to Imitate from a Single Video Demonstration
Glen Berseth.

Imitation learning, the ability to reproduce some behaviour, is a challenging and vital problem. It is what enables animals with the ability to understand and mimic from observation. Many SoTA methods for imitation accomplish this via additional data that is often not available in the real world. For example, along with an expert's joint positions, the torques used by the expert are available as well. In this work, we describe a learning system that allows an agent to reproduce imitative behaviour of 3D simulated robots from video. This progress will enable us to create robots that can learn behaviour from observing humans, and allow humans to instruct robots in a very natural form of instruction.
March 2023.
Data Science Course (IFT6758B)
Glen Berseth.
I teach a course on Data Science that covers the most imprtant concepts needed for students to become good data scientists.
September 2022.
Montreal Robotics Summer School (2022)
Glen Berseth.
 |  |  |
| The Go1 hardware | Practicing with hardware | This years champions |
Robotics is a rapidly growing field with interest from around the world. This summer school offers tutorials and lectures on state-of-the-art machine learning methods for training the next generation of learning robots. This summer school is an extension supported by the many robotics groups around Montreal.
August 2022.
Course in Robot (real-world-agent) Learning
Glen Berseth.
 |  |  |
| Learning from images | Learning reward functions | Learning in the real world |
I teach a course on machine learning for the real world. This course focuses on deep reinforcement learning methods and their application to control real world systems (robotics, etc). [Here](https://diro.umontreal.ca/public/FAS/diro/Documents/1-Programmes-cours/Horaires/2023Hiver2Cyc.html) is a link to where you can find the course offered on the DIRO web page as IFT 6163.
September 2021.
XT2: Training an X-to-Text Typing Interface with Online Learning from Implicit Feedback
Glen Berseth.
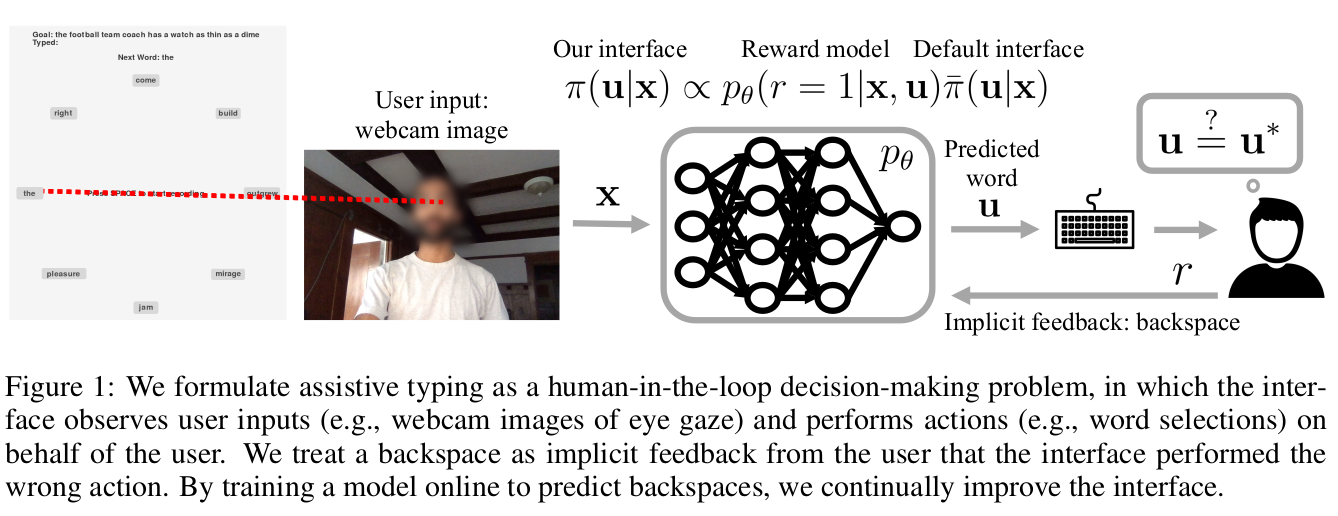
We aim to help users communicate their intent to machines using flexible, adaptive interfaces that translate arbitrary user input into desired actions. In this work, we focus on assistive typing applications in which a user cannot operate a keyboard, but can instead supply other inputs, such as webcam images that capture eye gaze. Standard methods train a model on a fixed dataset of user inputs, then deploy a static interface that does not learn from its mistakes; in part, because extracting an error signal from user behavior can be challenging. We investigate a simple idea that would enable such interfaces to improve over time, with minimal additional effort from the user: online learning from user feedback on the accuracy of the interface's actions. In the typing domain, we leverage backspaces as feedback that the interface did not perform the desired action. We propose an algorithm called x-to-text (X2T) that trains a predictive model of this feedback signal, and uses this model to fine-tune any existing, default interface for translating user input into actions that select words or characters. We evaluate X2T through a small-scale online user study with 12 participants who type sentences by gazing at their desired words, and a large-scale observational study on handwriting samples from 60 users. The results show that X2T learns to outperform a non-adaptive default interface, stimulates user co-adaptation to the interface, personalizes the interface to individual users, and can leverage offline data collected from the default interface to improve its initial performance and accelerate online learning.
November 2020.
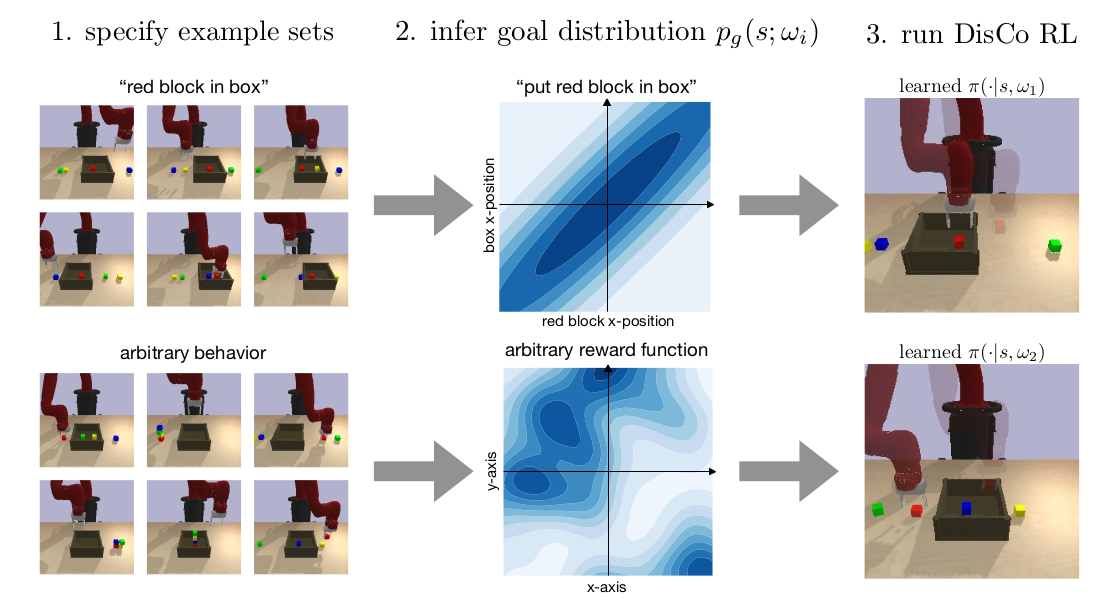
DisCo RL: Distribution-Conditioned Reinforcement Learning for General-Purpose Policies
Glen Berseth.
Can we use reinforcement learning to learn general-purpose policies that can perform a wide range of different tasks, resulting in flexible and reusable skills? Contextual policies provide this capability in principle, but the representation of the context determines the degree of generalization and expressivity. Categorical contexts preclude generalization to entirely new tasks. Goal-conditioned policies may enable some generalization, but cannot capture all tasks that might be desired. In this paper, we propose goal distributions as a general and broadly applicable task representation suitable for contextual policies. Goal distributions are general in the sense that they can represent any state-based reward function when equipped with an appropriate distribution class, while the particular choice of distribution class allows us to trade off expressivity and learnability. We develop an off-policy algorithm called distribution-conditioned reinforcement learnin (DisCo) to efficiently learn these policies. We evaluate DisCo on a variety of robot manipulation tasks and find that it significantly outperforms prior methods on tasks that require generalization to new goal distributions.
November 2020.
Deep Integration of Physical Humanoid Control and Crowd Navigation
Glen Berseth.
 |  |

Many multi-agent navigation approaches make use of simplified representations such as a disk. These simplifications allow for fast simulation of thousands of agents but limit the simulation accuracy and fidelity. In this paper, we propose a fully integrated physical character control and multi-agent navigation method. In place of sample complex online planning methods, we extend the use of recent deep reinforcement learning techniques. This extension improves on multi-agent navigation models and simulated humanoids by combining Multi-Agent and Hierarchical Reinforcement Learning. We train a single short term goal-conditioned low-level policy to provide directed walking behaviour. This task-agnostic controller can be shared by higher-level policies that perform longer-term planning. The proposed approach produces reciprocal collision avoidance, robust navigation, and emergent crowd behaviours. Furthermore, it offers several key affordances not previously possible in multi-agent navigation including tunable character morphology and physically accurate interactions with agents and the environment. Our results show that the proposed method outperforms prior methods across environments and tasks, as well as, performing well in terms of zero-shot generalization over different numbers of agents and computation time.
October 2020.
Inter-Level Cooperation in Hierarchical Reinforcement Learning
Glen Berseth.

Hierarchical models for deep reinforcement learning (RL) have emerged as powerful methods for generating meaningful control strategies in difficult long time horizon tasks. Training of said hierarchical models, however, continue to suffer from instabilities that limit their applicability. In this paper, we address instabilities that arise from the concurrent optimization of goal-assignment and goal-achievement policies. Drawing connections between this concurrent optimization scheme and communication and cooperation in multi-agent RL, we redefine the standard optimization procedure to explicitly promote cooperation between these disparate tasks. Our method is demonstrated to achieve superior results to existing techniques in a set of difficult long time horizon tasks, and serves to expand the scope of solvable tasks by hierarchical reinforcement learning.
August 2020.
Ecological Reinforcement Learning
Glen Berseth.
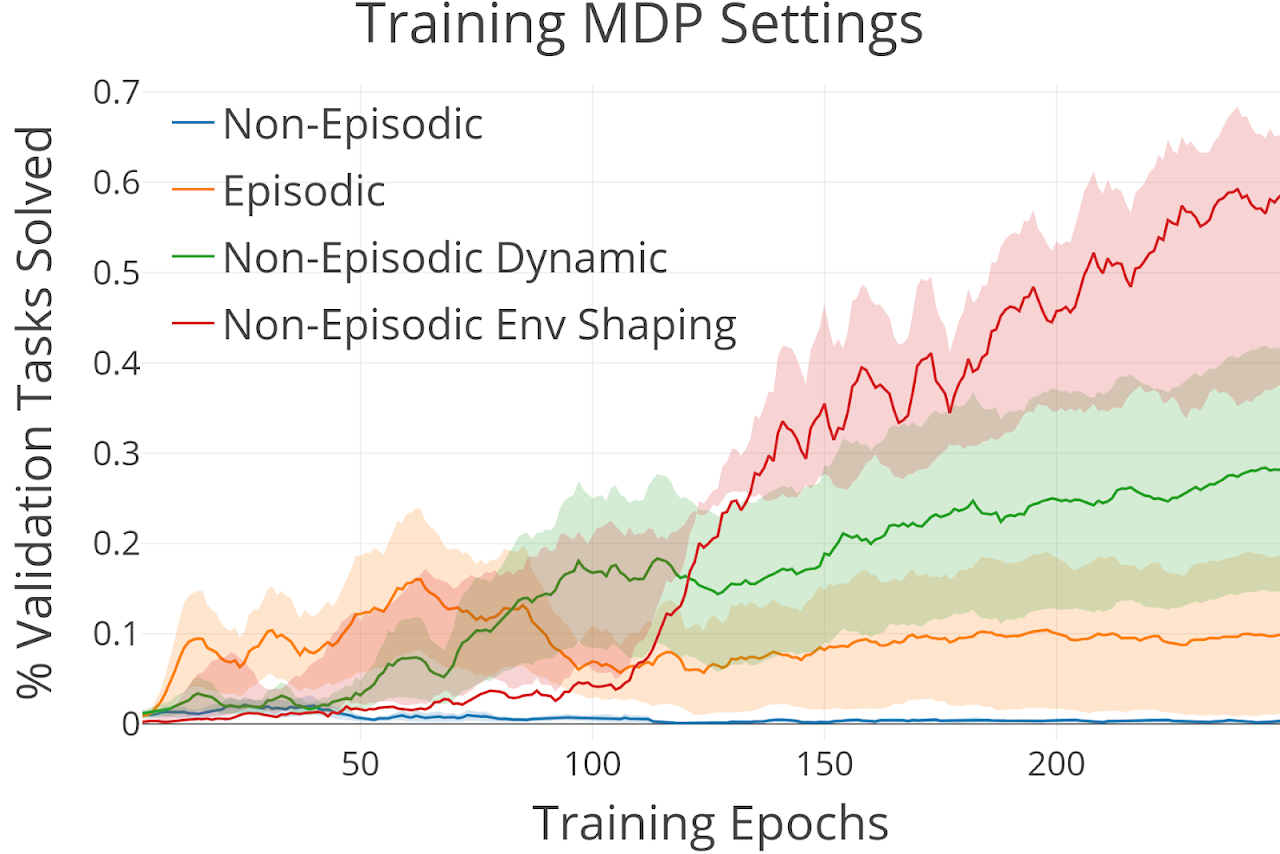
Reinforcement learning is normally studied in the episodic setting where the agent is reset each episode. This makes learning easier but in the real world, we would like our agent to continually learn with minimal human supervision and without having to manually reset the agent each time it makes a mistake. Reset-free or non-episodic learning is difficult, especially with sparse reward where the agent may never experience any rewarding states and not make any progress. Without any algorithmic changes however, certain properties of the environment can make learning without resets and with sparse reward more tractable. We investigate and analyze these properties: environment shaping and environment dynamism.
August 2020.
Morphology-Agnostic Visual Robotic Control
Glen Berseth.
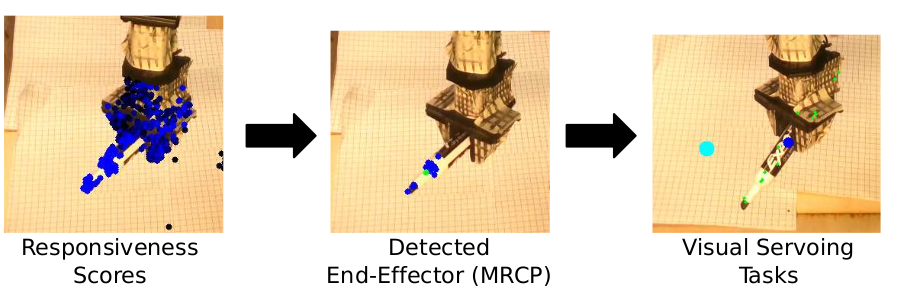
Existing approaches for visuomotor robotic control typically require characterizing the robot in advance by calibrating the camera or performing system identification. We propose MAVRIC, an approach that works with minimal prior knowledge of the robot's morphology, and requires only a camera view containing the robot and its environment and an unknown control interface. MAVRIC revolves around a mutual information-based method for self-recognition, which discovers visual "control points" on the robot body within a few seconds of exploratory interaction, and these control points in turn are then used for visual servoing. MAVRIC can control robots with imprecise actuation, no proprioceptive feedback, unknown morphologies including novel tools, unknown camera poses, and even unsteady handheld cameras. We demonstrate our method on visually-guided 3D point reaching, trajectory following, and robot-to-robot imitation.
March 2020.
SMiRL: Surprise Minimizing RL in Unstable Environments
Glen Berseth.
 | 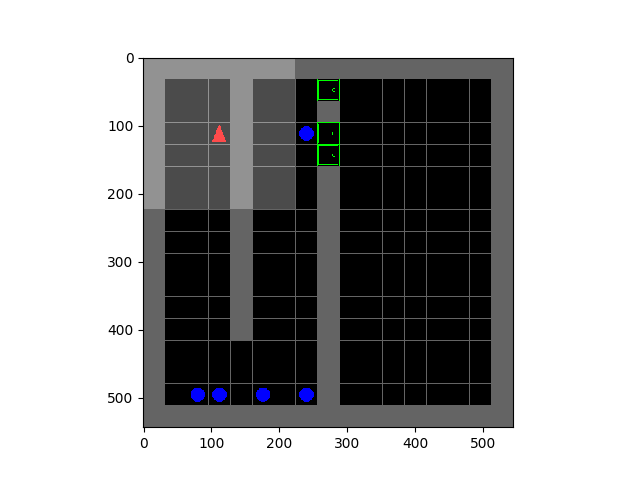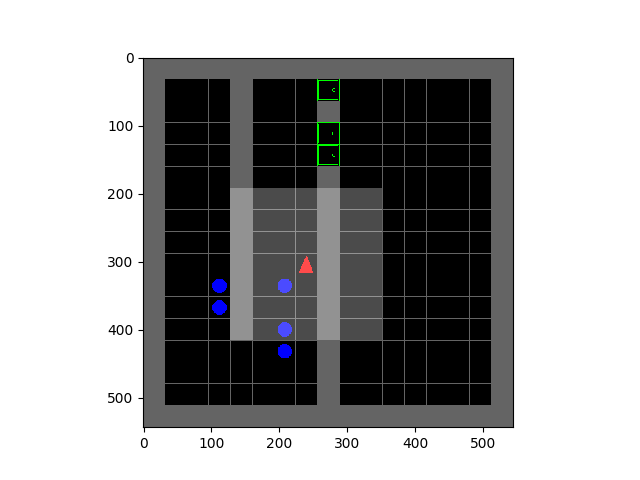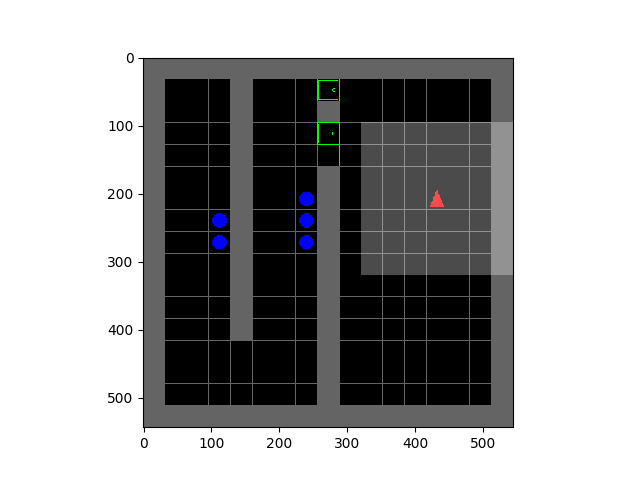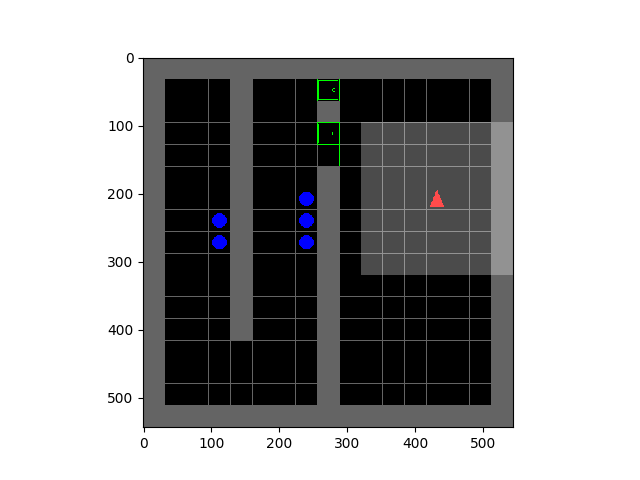 |
All living organisms carve out environmental niches within which they can maintain relative predictability amidst the ever-increasing entropy around them [schneider1994, friston2009]. Humans, for example, go to great lengths to shield themselves from surprise --- we band together in millions to build cities with homes, supplying water, food, gas, and electricity to control the deterioration of our bodies and living spaces amidst heat and cold, wind and storm. The need to discover and maintain such surprise-free equilibria has driven great resourcefulness and skill in organisms across very diverse natural habitats. Motivated by this, we ask: could the motive of preserving order amidst chaos guide the automatic acquisition of useful behaviors in artificial agents?
December 2019.
Contextual Imagined Goals for Self-Supervised Robotic Learning
Glen Berseth.
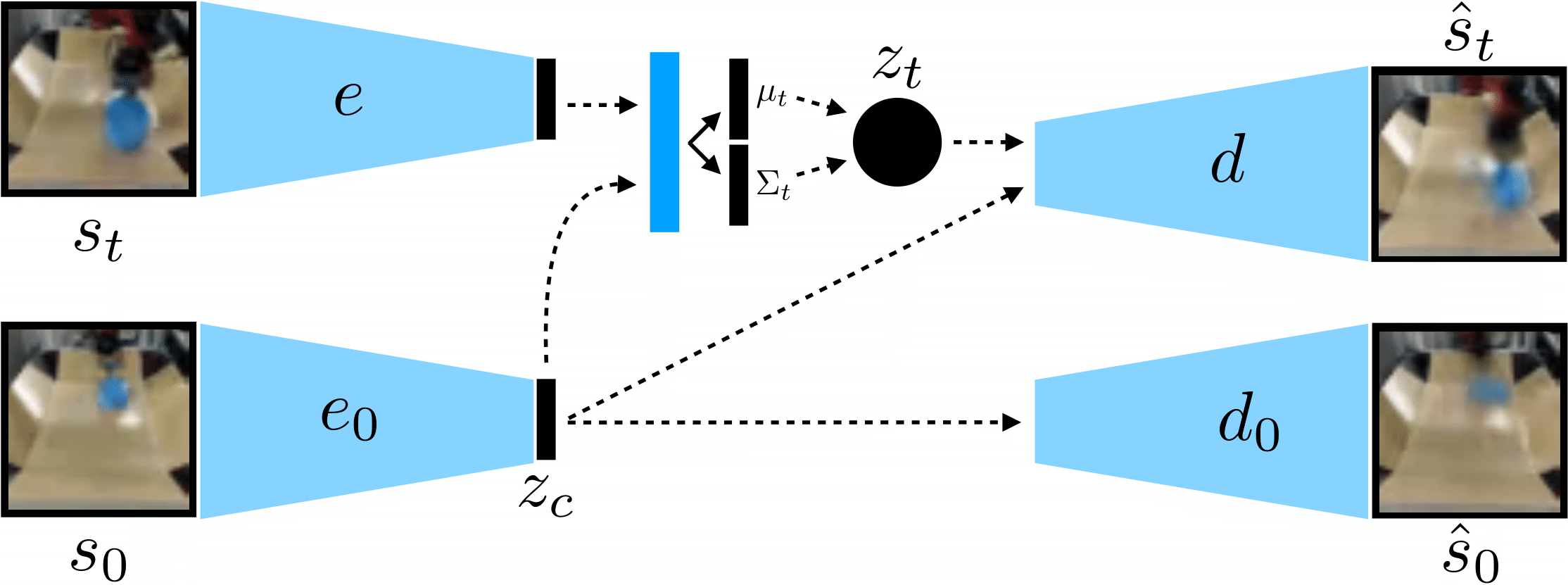
While reinforcement learning provides an appealing formalism for learning individual skills, a general-purpose robotic system must be able to master an extensive repertoire of behaviors. Instead of learning a large collection of skills individually, can we instead enable a robot to propose and practice its own behaviors automatically, learning about the affordances and behaviors that it can perform in its environment, such that it can then repurpose this knowledge once a new task is commanded by the user? In this paper, we study this question in the context of self-supervised goal-conditioned reinforcement learning. A central challenge in this learning regime is the problem of goal setting: in order to practice useful skills, the robot must be able to autonomously set goals that are feasible but diverse. When the robot's environment and available objects vary, as they do in most open-world settings, the robot must propose to itself only those goals that it can accomplish in its present setting with the objects that are at hand. Previous work only studies self-supervised goal-conditioned RL in a single-environment setting, where goal proposals come from the robot's past experience or a generative model are sufficient. In more diverse settings, this frequently leads to impossible goals and, as we show experimentally, prevents effective learning. We propose a conditional goal-setting model that aims to propose goals that are feasible from the robot's current state. We demonstrate that this enables self-supervised goal-conditioned off-policy learning with raw image observations in the real world, enabling a robot to manipulate a variety of objects and generalize to new objects that were not seen during training.
October 2019.
Interactive Architectural Design with Diverse Solution Exploration
Glen Berseth.
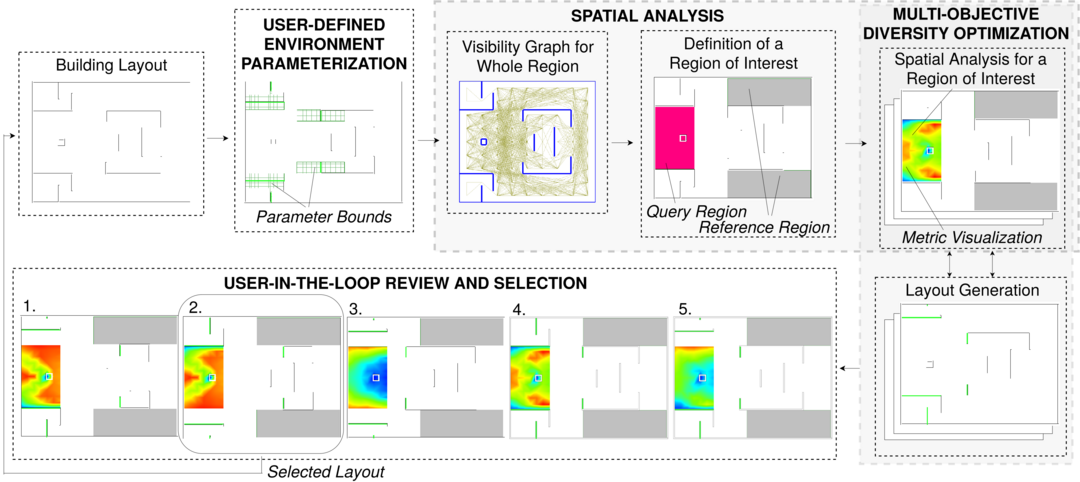
In architectural design, architects explore a vast amount of design options to maximize various performance criteria, while adhering to specific constraints. In an effort to assist architects in such a complex endeavour, we propose IDOME, an interactive system for computer-aided design optimization. Our approach balances automation and control by efficiently exploring, analyzing, and filtering space layouts to inform architects' decision-making better. At each design iteration, IDOME provides a set of alternative building layouts which satisfy user-defined constraints and optimality criteria concerning a user-defined space parametrization. When the user selects a design generated by IDOME, the system performs a similar optimization process with the same (or different) parameters and objectives. A user may iterate this exploration process as many times as needed. In this work, we focus on optimizing built environments using architectural metrics by improving the degree of visibility, accessibility, and information gaining for navigating a proposed space. This approach, however, can be extended to support other kinds of analysis as well. We demonstrate the capabilities of IDOME through a series of examples, performance analysis, user studies, and a usability test. The results indicate that IDOME successfully optimizes the proposed designs concerning the chosen metrics and offers a satisfactory experience for users with minimal training.
October 2019.
Gamification of Crowd-Driven Environment Design
Glen Berseth.
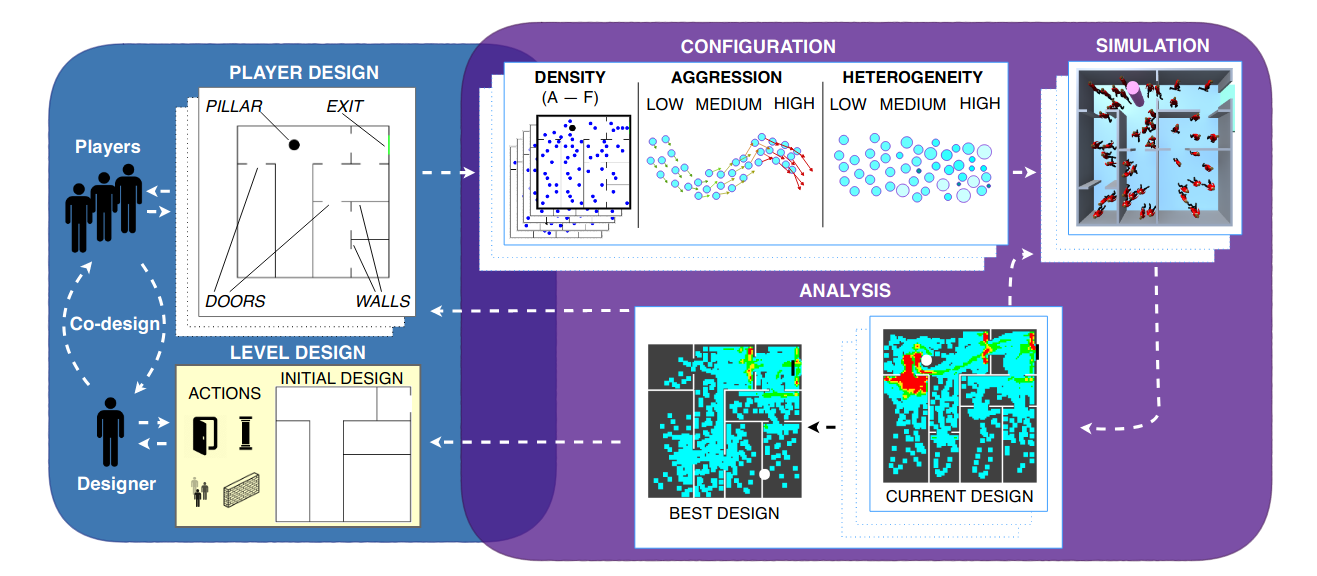
This paper describes using human creativity within a gamified collaborative design framework to address the complexity of predictive environment design. This framework is predicated on gamifying crowd objectives and presenting environment design problems as puzzles. A usability study reveals that the framework is considered usable for the task. Participants were asked to configure an environment puzzle to reduce an important crowd metric, the total egress time. The design task was constructed to be straightforward and uses a simplified environment as a probe for understanding the utility of gamification and the performance of collaboration. Single-player and multiplayer designs outperformed both optimization and expert-sourced designs of the same environment and multiplayer designs further outperformed the single-player designs. Single-player and multiplayer iterations followed linear and exponential decrease trends in total egress time respectively. Our experiments provide strong evidence towards an interesting novel approach of crowdsourcing collaborative environment design.
June 2019.
Model-Based Action Exploration for Learning Dynamic Motion Skills
Glen Berseth.
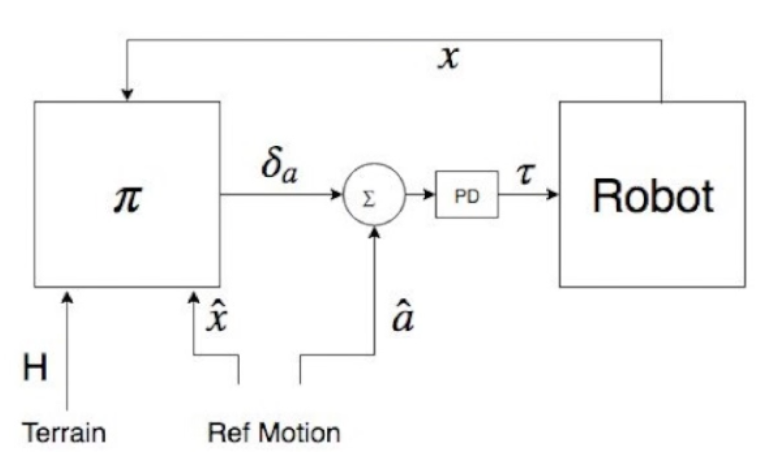
Deep reinforcement learning has achieved great strides in solving challenging motion control tasks. Recently, there has been significant work on methods for exploiting the data gathered during training, but there has been less work on how to best generate the data to learn from. For continuous action domains, the most common method for generating exploratory actions involves sampling from a Gaussian distribution centred around the mean action output by a policy. Although these methods can be quite capable, they do not scale well with the dimensionality of the action space, and can be dangerous to apply on hardware. We consider learning a forward dynamics model to predict the result, $(x_{t+1})$, of taking a particular action, $(u_{t})$, given a specific observation of the state, $(x_{t})$. With this model we perform internal look-ahead predictions of outcomes and seek actions we believe have a reasonable chance of success. This method alters the exploratory action space, thereby increasing learning speed and enables higher quality solutions to difficult problems, such as robotic locomotion and juggling
September 2018.
Feedback Control for Cassie with Deep Reinforcement Learning
Glen Berseth.
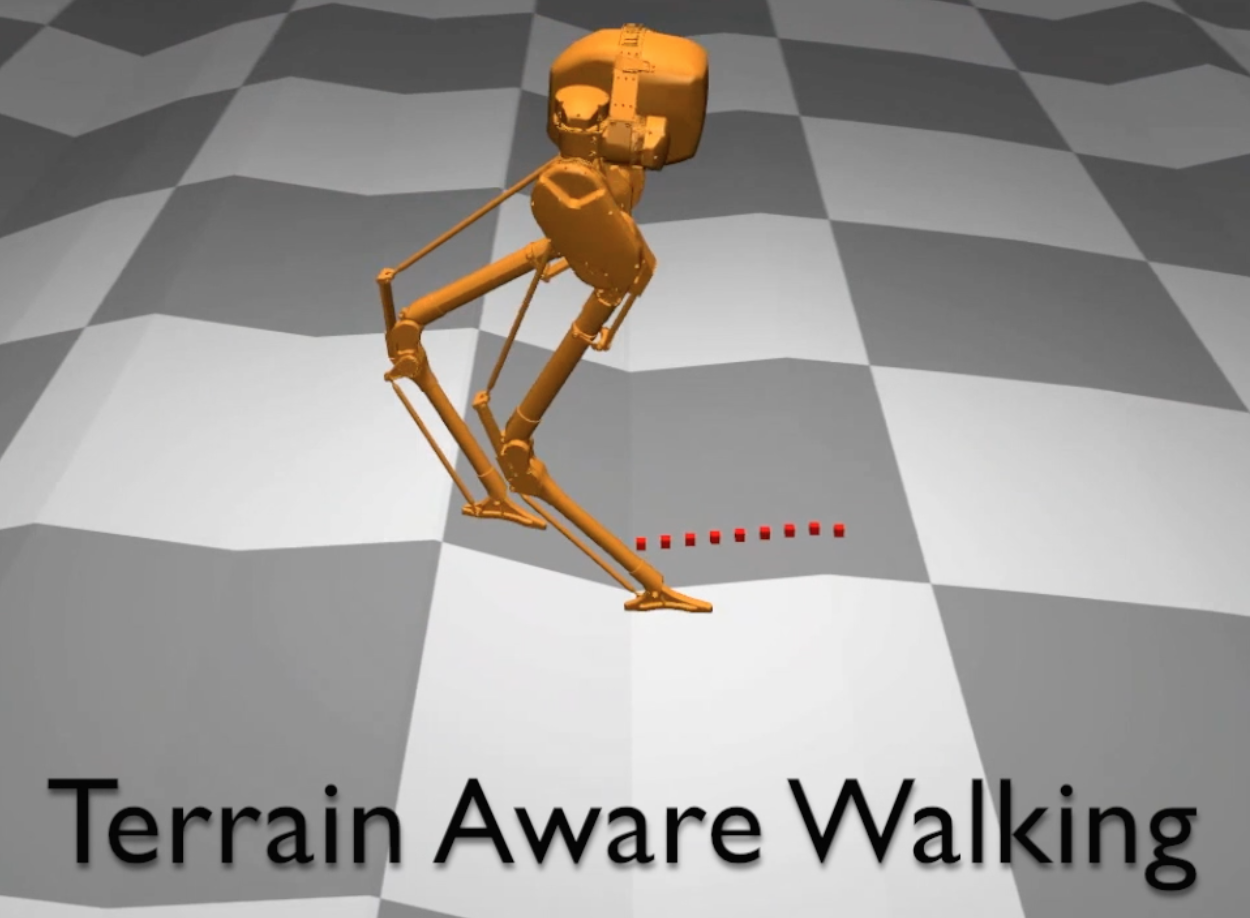
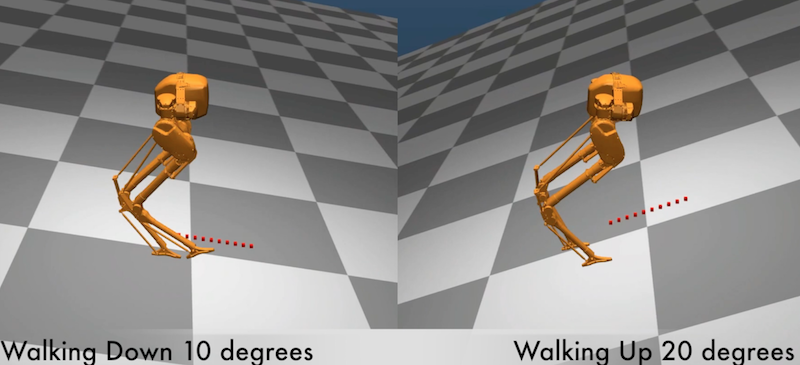
Deep reinforcement learning has achieved great strides in solving challenging motion control tasks. Recently, there has been significant work on methods for exploiting the data gathered during training, but there has been less work on how to best generate the data to learn from. For continuous action domains, the most common method for generating exploratory actions involves sampling from a Gaussian distribution centred around the mean action output by a policy. Although these methods can be quite capable, they do not scale well with the dimensionality of the action space, and can be dangerous to apply on hardware. We consider learning a forward dynamics model to predict the result, $(x_{t+1})$, of taking a particular action, $(u_{t})$, given a specific observation of the state, $(x_{t})$. With this model we perform internal look-ahead predictions of outcomes and seek actions we believe have a reasonable chance of success. This method alters the exploratory action space, thereby increasing learning speed and enables higher quality solutions to difficult problems, such as robotic locomotion and juggling
September 2018.
TerrainRL Sim
Glen Berseth.
We provide 88 challenging simulation environments that range in difficulty. The difficulty in these environments is linked not only to the number of dimensions in the action space but also to the task complexity. Using more complex and accurate simulations will help push the field closer to creating human-level intelligence. Therefore, we are releasing a number of simulation environments that include local egocentric visual perception. These environments include randomly generated terrain which the agent needs to learn to interpret via visual features. The library also provides simple mechanisms to create new environments with different agent morphologies and the option to modify the distribution of generated terrain.
April 2018.
Progressive Reinforcement Learning with Distillation for Multi-Skilled Motion Control
Glen Berseth.
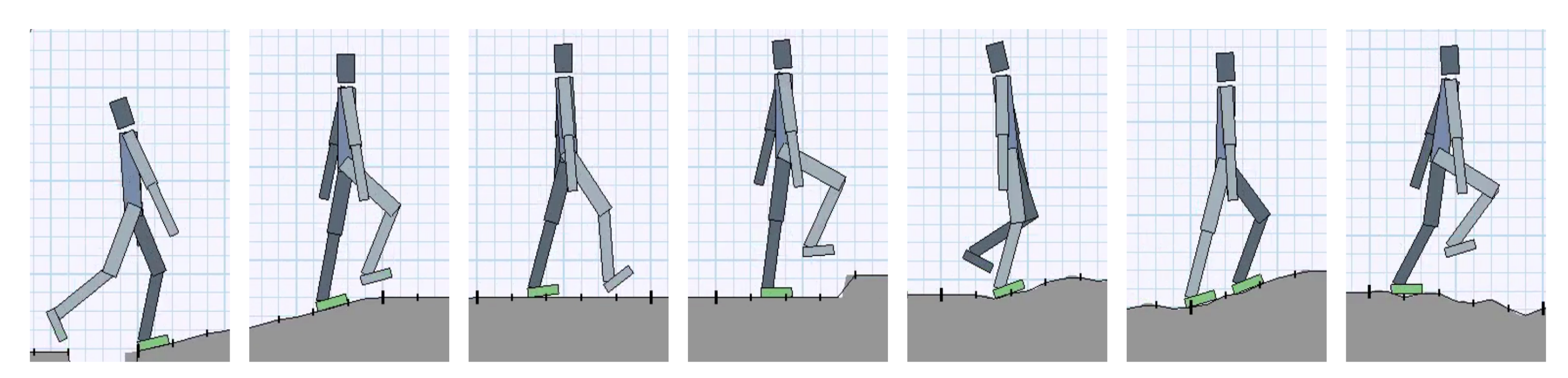
Deep reinforcement learning has demonstrated increasing capabilities for continuous control problems, including agents that can move with skill and agility through their environment. An open problem in this setting is that of developing good strategies for integrating or merging policies for multiple skills, where each individual skill is a specialist in a specific skill and its associated state distribution. We extend policy distillation methods to the continuous action setting and leverage this technique to combine expert policies, as evaluated in the domain of simulated bipedal locomotion across different classes of terrain. We also introduce an input injection method for augmenting an existing policy network to exploit new input features. Lastly, our method uses transfer learning to assist in the efficient acquisition of new skills. The combination of these methods allows a policy to be incrementally augmented with new skills. We compare our progressive learning and integration via distillation (PLAID) method against three alternative baselines.
February 2018.
Demystifying the Many Deep Reinforcement Learning Algorithms
.
In recent years, there has been an explosion in Deep Reinforcement learning research resulting in the creation of many different RL algorithms that work with deep networks. In DeepRL and RL, in general, the goal is to optimize a policy $$\pi(a|s,\theta)$$ with parameters $$\theta$$ with respect to the future discounted reward. $$J(\pi) = \mathbb{E} [\sum_\limits{t=0}^{T} \gamma^{t} r_{t}]$$ It can be difficult to keep track of the many algorithms let alone their properties and when it is best to use which one. In this post, I make an effort to organize several RL methods into a few groups. This organization helps clear up some misconceptions of different algorithms and demystifies what these properties mean, for example, on-policy vs off-policy.
January 2018.
Evaluating and Optimizing Evacuation Plans for Crowd Egress
Glen Berseth.
Evacuation planning is an important and difficult task in building design. The proposed framework can identify optimal evacuation plans using decision points, which control the ratio of agents that select a particular route at a specific spatial location. The authors optimize these ratios to achieve the best evacuation based on a quantitatively validated metric for evacuation performance. This metric captures many of the important aspects of an evacuation: total evacuation time, average evacuation time, agent speed, and local agent density. The proposed approach was validated using a night club model that incorporates real data from an actual evacuation.
November 2017.
DeepLoco: Dynamic Locomotion Skills Using Hierarchical Deep Reinforcement Learning
Glen Berseth.

Learning physics-based locomotion skills is a difficult problem, leading to solutions that typically exploit prior knowledge of various forms. In this paper, we aim to learn a variety of environment-aware locomotion skills with a limited amount of prior knowledge. We adopt a two-level hierarchical control framework. First, low-level controllers are learned that operate at a fine timescale and which achieve robust walking gaits that satisfy stepping-target and style objectives. Second, high-level controllers are then learned which plan at the timescale of steps by invoking desired step targets for the low-level controller. The high-level controller makes decisions directly based on high-dimensional inputs, including terrain maps or other suitable representations of the surroundings. Both levels of the control policy are trained using deep reinforcement learning. Results are demonstrated on a simulated 3D biped. Low-level controllers are learned for a variety of motion styles and demonstrate robustness with respect to force-based disturbances, terrain variations, and style interpolation. High-level controllers are demonstrated that are capable of following trails through terrains, dribbling a soccer ball towards a target location, and navigating through static or dynamic obstacles.
May 2017.
Towards Computer Assisted Crowd Aware Architectural Design
Glen Berseth.
We present a preliminary exploration of an architectural optimization process towards a computational tool for designing environments (e.g., building floor plans). Using dynamic crowd simulators we derive the fitness of architectural layouts. The results of the simulation are used to provide feedback to a user in terms of crowd animation, aggregate statistics, and heat maps. Our approach automatically optimizes the placement of environment elements to maximize the flow of the crowd, while satisfying constraints that are imposed by the user (e.g., immovable walls or support bearing structures). We take steps towards user-in-the-loop optimization and design of an environment by applying an adaptive refinement approach to reduce the search space of the optimization. We perform a small scale user study to obtain early feedback on the performance and quality of our method in contrast with a manual approach.
November 2016.
Using synthetic crowds to inform building pillar placements
Glen B.
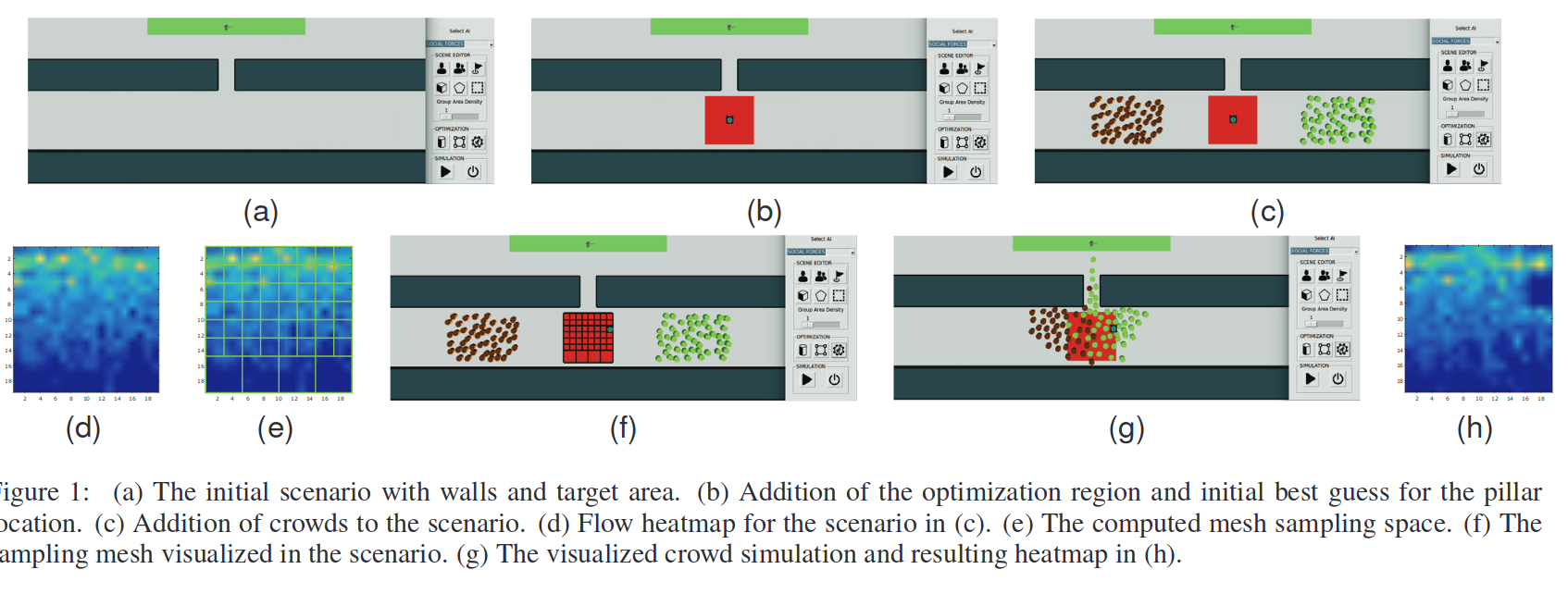
We present a preliminary exploration of synthetic crowds towards computational tools for informing the design of environments (e.g., building floor plans). Feedback and automatic design processes are developed from exploring crowd behaviours and metrics derived from simulations of environments in density stressed scenarios, such as evacuations. Computational approaches for crowd analysis and environment design benefit from measures characterizing the relationships between environments and crowd flow behaviours. We investigate the optimization of environment elements to maximize crowd flow, under a range of LoS conditions, a standard indicator for characterizing the service afforded by environments to crowds of specific densities widely used in crowd management and urban design. The steering algorithm, the number of optimized environment elements, the scenario configuration and the LoS conditions affect the optimal configuration of environment elements. From the insights gained exploring optimizations under LoS conditions, we take steps towards user-in-the-loop optimization and design of an environment by applying an adaptive refinement approach to reduce the search space of the optimization. We derive the fitness of architectural layouts from background simulations. We perform a ground truth study to gauge the performance and quality of our method.
May 2016.
Terrain Adaptive Locomotion Skills using Deep Reinforcement Learning
Glen Berseth.

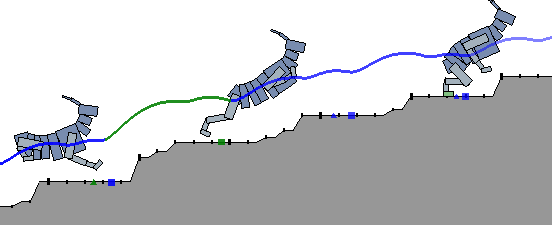
Reinforcement learning offers a promising methodology for developing skills for simulated characters, but typically requires working with sparse hand-crafted features. Building on recent progress in deep reinforcement learning (DeepRL), we introduce a mixture of actor-critic experts (MACE) approach that learns terrain-adaptive dynamic locomotion skills using high-dimensional state and terrain descriptions as input, and parameterized leaps or steps as output actions. MACE learns more quickly than a single actor-critic approach and results in actor-critic experts that exhibit specialization. Additional elements of our solution that contribute towards efficient learning include Boltzmann exploration and the use of initial actor biases to encourage specialization. Results are demonstrated for multiple planar characters and terrain classes.
May 2016.
Modeling Dynamic Brachiation
Glen Berseth.
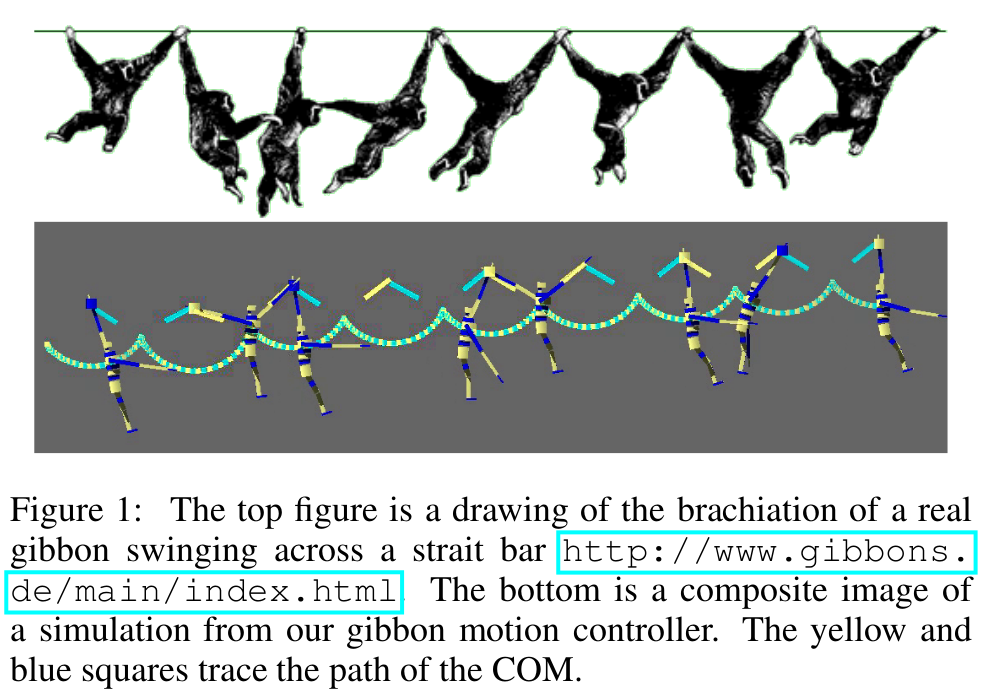
Significant progress has been made with regard to motions such as walking, running, and other specific motions, such as falling and rolling. However, we still have difficulty simulating agile motions we see in nature, for example, brachiation by gibbons. Gibbons are one of the most agile primates and can leap remarkable distances. In this work we discuss the advantages of skill learning with explicit planning to create motion controllers for more complex and dynamic navigation tasks. Skill learning is complex and cannot be directly solved using only supervised learning because generating good data plays a key role in learning good skills. Here we construct a FSM controller to model the motion and capabilities of a gibbon, one of the most agile primates, shown in Figure 1. We endeavour to give this controller motion skills using reinforcement learning and use this dynamics model to intelligently sample good actions.
May 2016.
Dynamic terrain traversal skills using reinforcement learning
Glen Berseth.

The locomotion skills developed for physics-based characters most often target flat terrain. However, much of their potential lies with the creation of dynamic, momentum-based motions across more complex terrains. In this paper, we learn controllers that allow simulated characters to traverse terrains with gaps, steps, and walls using highly dynamic gaits. This is achieved using reinforcement learning, with careful attention given to the action representation, non-parametric approximation of both the value function and the policy; epsilon-greedy exploration; and the learning of a good state distance metric. The methods enable a 21-link planar dog and a 7-link planar biped to navigate challenging sequences of terrain using bounding and running gaits. We evaluate the impact of the key features of our skill learning pipeline on the resulting performance.
May 2016.
ACCLMesh: Curvature-Based Navigation Mesh Generation
Glen Berseth.


The proposed method robustly and efficiently computes a navigation mesh for arbitrary and dynamic 3D environments based on curvature. This method addresses a number of known limitations in state-of-the-art techniques to produce navigation meshes that are tightly coupled to the original geometry, incorporate geometric details that are crucial for movement decisions and can robustly handle complex surfaces. The method is integrated into a standard navigation and collision-avoidance system to simulate thousands of agents on complex 3D surfaces in real-time.
April 2016.
Evaluating and Optimizing Level of Service for Crowd Evacuations
Glen B.
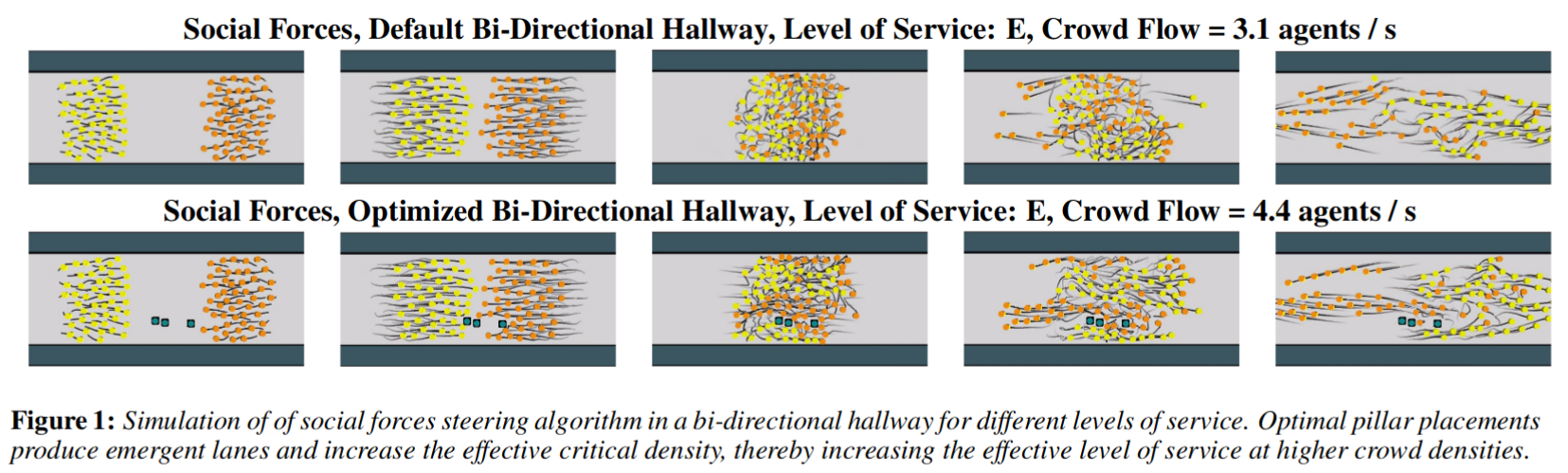
Computational approaches for crowd analysis and environment design need robust measures for characterizing the relation between environments and crowd flow. Level of service (Level of Service) is a standard indicator for characterizing the service afforded by environments to crowds of specific densities, and is widely used in crowd management and urban design. However, current Level of Service indicators are qualitative and rely on expert analysis. In this paper, we perform a systematic analysis of Level of Service for synthetic crowds. The flow-density relationships in crowd evacuation scenarios are explored with respect to three state-of-the-art steering algorithms. Our results reveal that Level of Service is sensitive to the crowd behavior, and the configuration of the environment benchmark. Following this study, we automatically optimize environment elements to maximize crowd flow, under a range of Level of Service conditions. The steering algorithm, the number of optimized environment elements, the scenario configuration and the Level of Service conditions affect the optimal configuration of environment elements. We observe that the critical density of crowd simulators increases due to the optimal placement of pillars, thereby effectively increasing the Level of Service of environments at higher crowd densities. Depending on the simulation technique and environment benchmark, pillars are configured to produce lanes or form wall-like structures, in an effort to maximize crowd flow. These experiments serve as an important precursor to computational crowd optimization and management and motivate the need for further study using additional real and synthetic crowd datasets across a larger representation of environment benchmarks.
May 2015.