University of British Columbia
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2018)
Zhaoming Xie (1), Glen Berseth (1), Patrick Clary (2), Jonathan Hurst (2), Michiel van de Panne (1)
(1) University of British Columbia (2) Oregon State University
Abstract
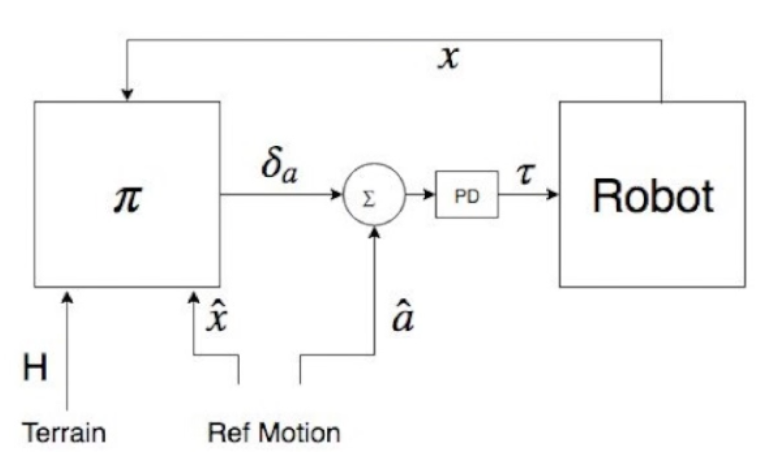
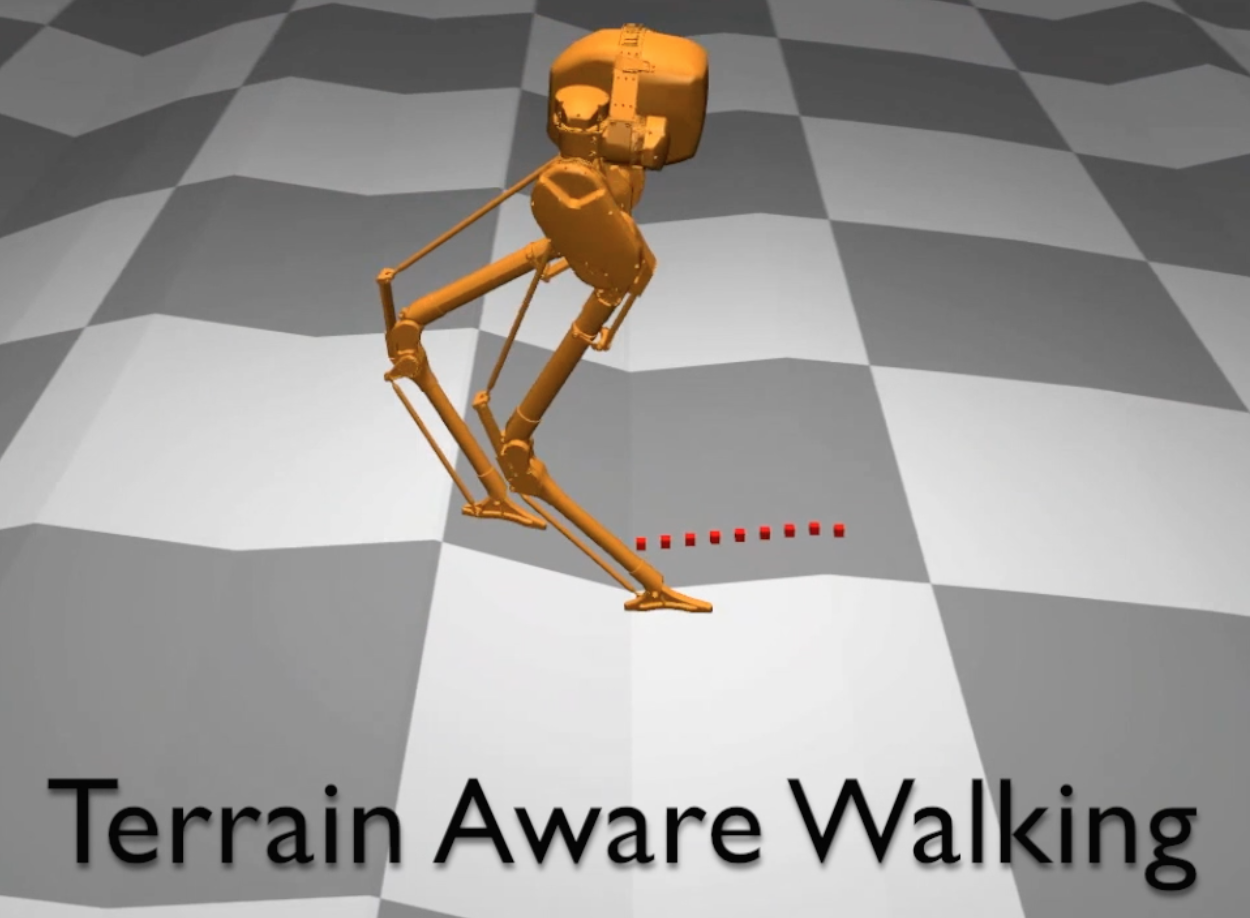
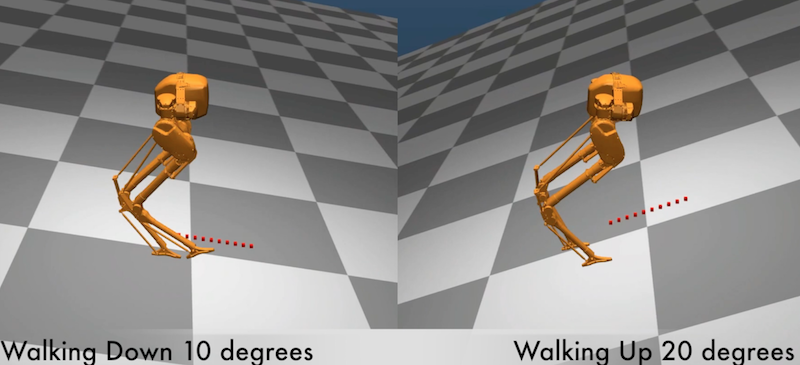
Bipedal locomotion skills are challenging to develop. Control strategies often use local linearization of the dynamics in conjunction with reduced-order abstractions to yield tractable solutions. In these model-based control strategies, the controller is often not fully aware of many details, including torque limits, joint limits, and other non-linearities that are necessarily excluded from the control computations for simplicity. Deep reinforcement learning (DRL) offers a promising model-free approach for controlling bipedal locomotion which can more fully exploit the dynamics. However, current results in the machine learning literature are often based on ad-hoc simulation models that are not based on corresponding hardware. Thus it remains unclear how well DRL will succeed on realizable bipedal robots. In this paper, we demonstrate the effectiveness of DRL using a realistic model of Cassie, a bipedal robot. By formulating a feedback control problem as finding the optimal policy for a Markov Decision Process, we are able to learn robust walking controllers that imitate a reference motion with DRL. Controllers for different walking speeds are learned by imitating simple time- scaled versions of the original reference motion. Controller robustness is demonstrated through several challenging tests, including sensory delay, walking blindly on irregular terrain and unexpected pushes at the pelvis. We also show we can interpolate between individual policies and that robustness can be improved with an interpolated policy.
Files
Videos!
On real robot
Bibtex
@inproceedings{2018-IROS-cassie,
title={Feedback Control for Cassie with Deep Reinforcement Learning},
author={Zhaoming Xie and Glen Berseth and Patrick Clary and Jonathan Hurst and Michiel van de Panne},
booktitle = {Proc. IEEE/RSJ Intl Conf on Intelligent Robots and Systems (IROS 2018)},
year={2018}
}
Acknowledgements
We thank the anonymous reviewers for their helpful feedback. This research was funded in part by an NSERC Discovery Grant (RGPIN-2015-04843).