*Glen Berseth and *Cheng Xie and Paul Cernek and Michiel van de Panne
University of British Columbia
* Equal Contribution
Abstract
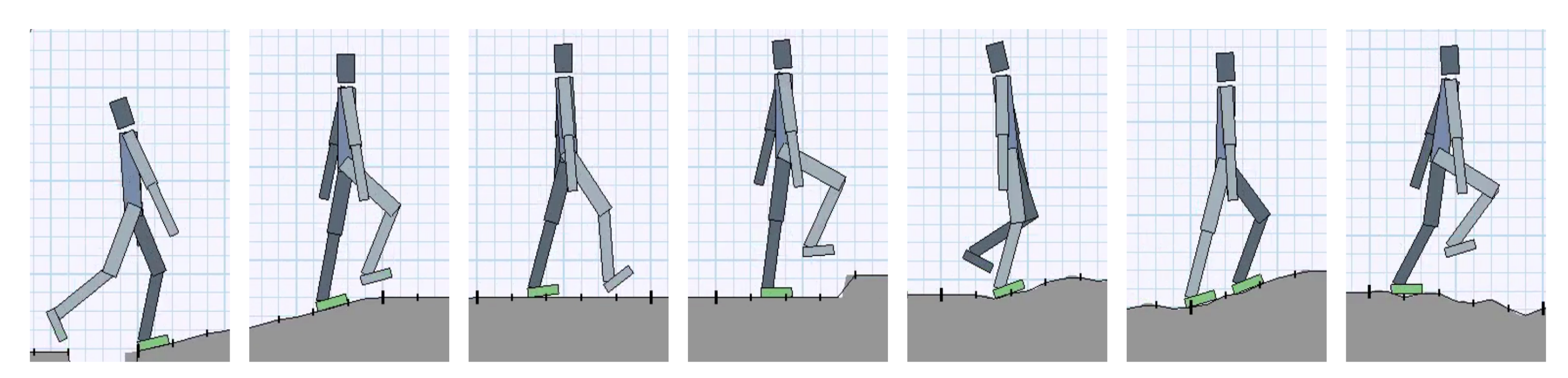
Deep reinforcement learning has demonstrated increasing capabilities for continuous control problems, including agents that can move with skill and agility through their environment. An open problem in this setting is that of developing good strategies for integrating or merging policies for multiple skills, where each individual skill is a specialist in a specific skill and its associated state distribution. We extend policy distillation methods to the continuous action setting and leverage this technique to combine expert policies, as evaluated in the domain of simulated bipedal locomotion across different classes of terrain. We also introduce an input injection method for augmenting an existing policy network to exploit new input features. Lastly, our method uses transfer learning to assist in the efficient acquisition of new skills. The combination of these methods allows a policy to be incrementally augmented with new skills. We compare our progressive learning and integration via distillation (PLAID) method against three alternative baselines.
Files
Paper Learning code Simulation Environment
Videos!
Bibtex
@article{2018-ICLR-PLAiD,
title={Progressive Reinforcement Learning with Distillation for Multi-Skilled Motion Control},
author={Glen Berseth and Cheng Xie and Paul Cernek and Michiel van de Panne},
journal = {International Conference on Learning Representations},
year={2018}
}
Acknowledgements
We thank the anonymous reviewers for their helpful feedback. This research was funded in part by an NSERC Discovery Grant (RGPIN-2015-04843).