Home
 |
I am an assistant professor at the Université de Montréal, a core academic member of the Mila - Quebec AI Institute, Canada CIFAR AI chair, member of L'Institut Courtois, and co-director of the Robotics and Embodied AI Lab (REAL).
I was a postdoctoral researcher with Berkeley Artificial Intelligence Research (BAIR), working with Sergey Levine.
My current research focuses on machine learning and solving real-world sequential decision-making problems (planning/RL), such as robotics, scientific discovery and adaptive clean technology. The specifics of this research have covered the areas of human-robot collaboration, generalization, reinforcement learning, continual learning, meta-learning, multi-agent learning, and hierarchical learning. I also teach courses on data science and robot learning at Université de Montréal and Mila, covering the most recent research on machine learning techniques for creating generalist agents. I have also co-created a new conference for reinforcement learning research.
For a more formal biography, click here |
- I support Slow Science.
- This short research statement explains my labs fundamental research goals.
News
-
(July 2026) New position paper accepted to ICML 2026 on Collusion Risks Among AI Reasoning Agents and why they justify certification requirements for making market decisions!
-
(January 2026) Three new papers accepted to ICLR 2025 on Efficient exploration with contrastive learning, Self-Predictive Representations for Combinatorial Generalization, and Use LLMs to generate structured reward functions!
-
(May 2025) Two new papers accepted to ICML 2025 on Outsourced diffusion models and Continual RL!
-
(January 2025) Three new papers accepted to ICLR 2025 on efficient imitation learning, exploration for GFNs, and real-time reinforcement learning!
-
(November 2024) Three new papers accepted to NeurIPS 2024 on inverse safe RL, converging and scaling deepRL algorithms, and amortizing intractable inference!
-
(August 2024) The first Conference on Reinforcement Learning was a blast!
-
(June 2024) New paper accepted to RSS 2024 on Making more diverse data sets for improving generalist robot policies!
-
(May 2024) Best paper award at ICLR to ICLR 2024 on VLMs for robotics!
-
(January 2024) Five new papers accepted to ICLR 2024 on efficient exploration, generalization in sequence planning for supervised learning, Intelligent Switching for Reset-Free RL, Using LLMs and RL for drug discovery, and Latent diffusion for OfflineRL!
-
(June 2022) New paper at IROS on quadruped robots learning soccer shooting skills. IROS Best RoboCup Paper Award Finalist!
-
(September 2021) New paper accepted to NeurIPS on surprise minimization in partially observed environments!
-
(April 2021) Our research paper that will be presented at ICRA2021 on RL for bipedal robots was featured in MIT Technology Review
Research Talk (2023)
Recent Research Talk (2023)
Recent Work
Autonomous real-world Reinforcement learning
| We study how robots can autonomously learn skills that require a combination of navigation and grasping. While reinforcement learning in principle provides for automated robotic skill learning, in practice reinforcement learning in the real world is challenging and often requires extensive instrumentation and supervision. Our aim is to devise a robotic reinforcement learning system for learning navigation and manipulation together, in an autonomous way without human intervention, enabling continual learning under realistic assumptions. Our proposed system, ReLMM, can learn continuously on a real-world platform without any environment instrumentation, without human intervention, and without access to privileged information, such as maps, objects positions, or a global view of the environment. Our method employs a modularized policy with components for manipulation and navigation, where manipulation policy uncertainty drives exploration for the navigation controller, and the manipulation module provides rewards for navigation. We evaluate our method on a room cleanup task, where the robot must navigate to and pick up items scattered on the floor. After a grasp curriculum training phase, ReLMM can learn navigation and grasping together fully automatically, in around 40 hours of autonomous real-world training. |
Generalization across robots via inferring morphology
| The prototypical approach to reinforcement learning involves training policies tailored to a particular agent from scratch for every new morphology. Recent work aims to eliminate the re-training of policies by investigating whether a morphology-agnostic policy, trained on a diverse set of agents with similar task objectives, can be transferred to new agents with unseen morphologies without re-training. This is a challenging problem that required previous approaches to use hand-designed descriptions of the new agent's morphology. Instead of hand-designing this description, we propose a data-driven method that learns a representation of morphology directly from the reinforcement learning objective. Ours is the first reinforcement learning algorithm that can train a policy to generalize to new agent morphologies without requiring a description of the agent's morphology in advance. We evaluate our approach on the standard benchmark for agent-agnostic control, and improve over the current state of the art in zero-shot generalization to new agents. Importantly, our method attains good performance without an explicit description of morphology. |
Entropy minimization for emergent behaviour 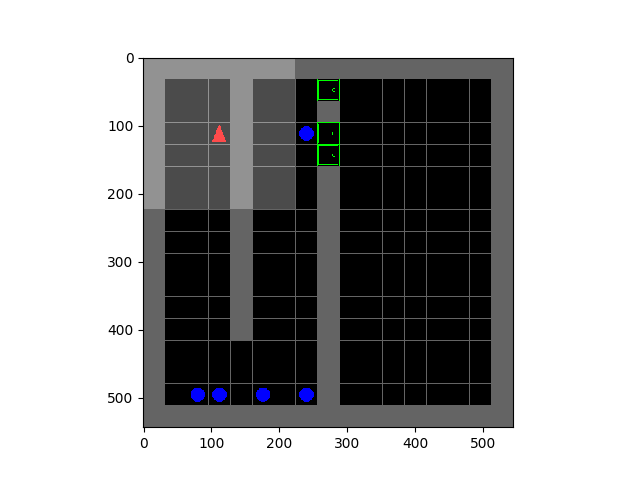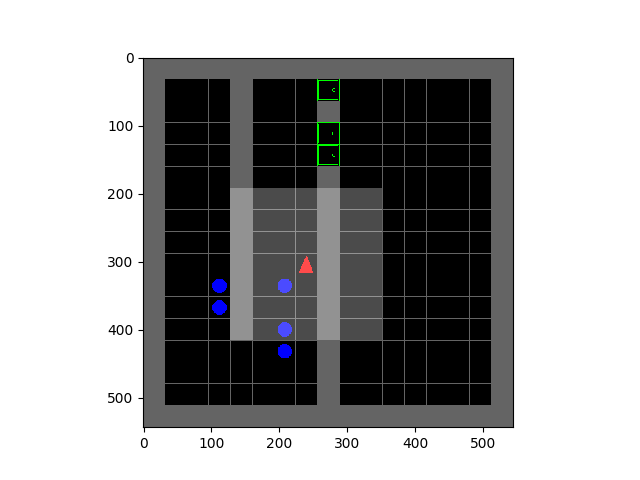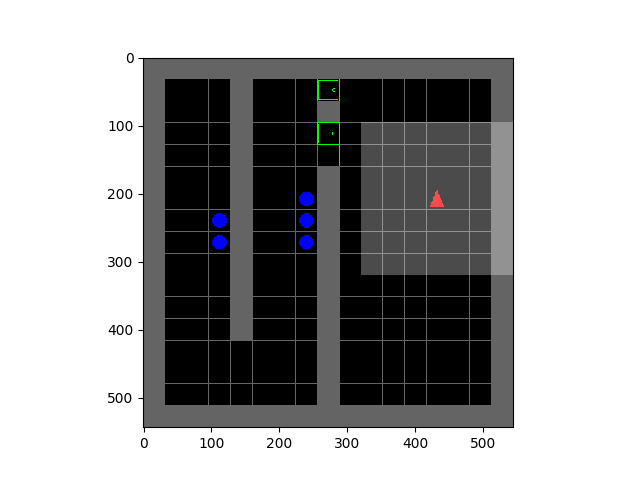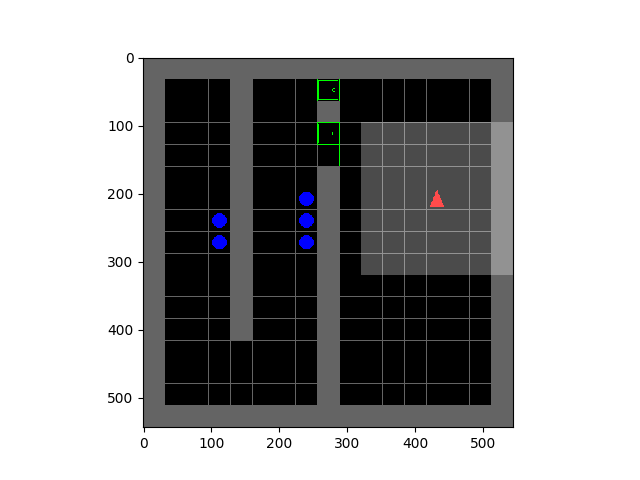 | All living organisms carve out environmental niches within which they can maintain relative predictability amidst the ever-increasing entropy around them [schneider1994, friston2009]. Humans, for example, go to great lengths to shield themselves from surprise --- we band together in millions to build cities with homes, supplying water, food, gas, and electricity to control the deterioration of our bodies and living spaces amidst heat and cold, wind and storm. The need to discover and maintain such surprise-free equilibria has driven great resourcefulness and skill in organisms across very diverse natural habitats. Motivated by this, we ask: could the motive of preserving order amidst chaos guide the automatic acquisition of useful behaviors in artificial agents? |