Glen Berseth, Florian Golemo, Christopher Pal
UdeM, Mila Quebec AI Institute, Canada CIFAR AI, Polytechnic Montreal, Service Now

Imitation learning, the ability to reproduce some behaviour, is a challenging and vital problem. It is what enables animals with the ability to understand and mimic from observation. Many SoTA methods for imitation accomplish this via additional data that is often not available in the real world. For example, along with an expert’s joint positions, the torques used by the expert are available as well. In this work, we describe a learning system that allows an agent to reproduce imitative behaviour of 3D simulated robots from video. This progress will enable us to create robots that can learn behaviour from observing humans, and allow humans to instruct robots in a very natural form of instruction.
Distance Learning
Often, imitation is posed as a distribution matching problem where we want to minimize a distance function that differentiates between behaviour that is close to the expert demonstration. If we have access to the expert’s actions, we can use semi-supervised learning. However, we rarely have access to such data in the real world. Instead, we can use visual perceptions to observe the expert and have the agent attempt actions until what it does matches what it observed. This method leads to two challenges. First, understanding if the agent’s behaviour matches the expert given only video data, by creating a meaningful distance metric. Second, enabling the agent to learn the actions necessary to match the expert.
While there has been work on imitation strategies from images for manipulation [BAIR] and 2D robots [GoogleBrain], the challenge of 3D imitation from video is an important milestone. Previous methods have made progress on imitation from images, by learning a transformation of images such that in this transformed space, meaningful distances are available. However, the problem of learning meaningful representations for planning or imitation is far from solved. A critical aspect of imitating a motion is the motions sequential and causal nature. The motion has both an ordering and a speed.
Imitation from Sequences



Current methods use spatial information to compute distances between images. These methods have worked well given enough compute, good policies can be learned. However, these methods may suffer from false negatives that occur when the agent is out-of-sync with the expert. In the above example, we show a walking motion, followed by a walking motion played back at $1/4$ speed and last, a fallen motion. The limitation of spatial distance methods is that a similar low reward will be given for these two examples, although, the middle motion looks more like a walk then the right.
In this work, we make use of the sequential structure of motion to inform deep reinforcement learning (RL) better. Effectively, we learn two distance functions, one in space and another in time. While the spatial distance function is designed to understand distances between pictures or poses, the time-based distance function understands if two motions look semantically similar. For example, if the imitation goal is to walk, does the agent’s behaviour also look like a walk? In effect, with this new abstraction, we can ask the question, does this motion look like a walk, not, does this motion look precisely like that walk. This distinction allows us to reward the agent for behaviour that is similar to the expert and may be at a different speed or time. This form of reward shaping was critical to learning good policies from video.
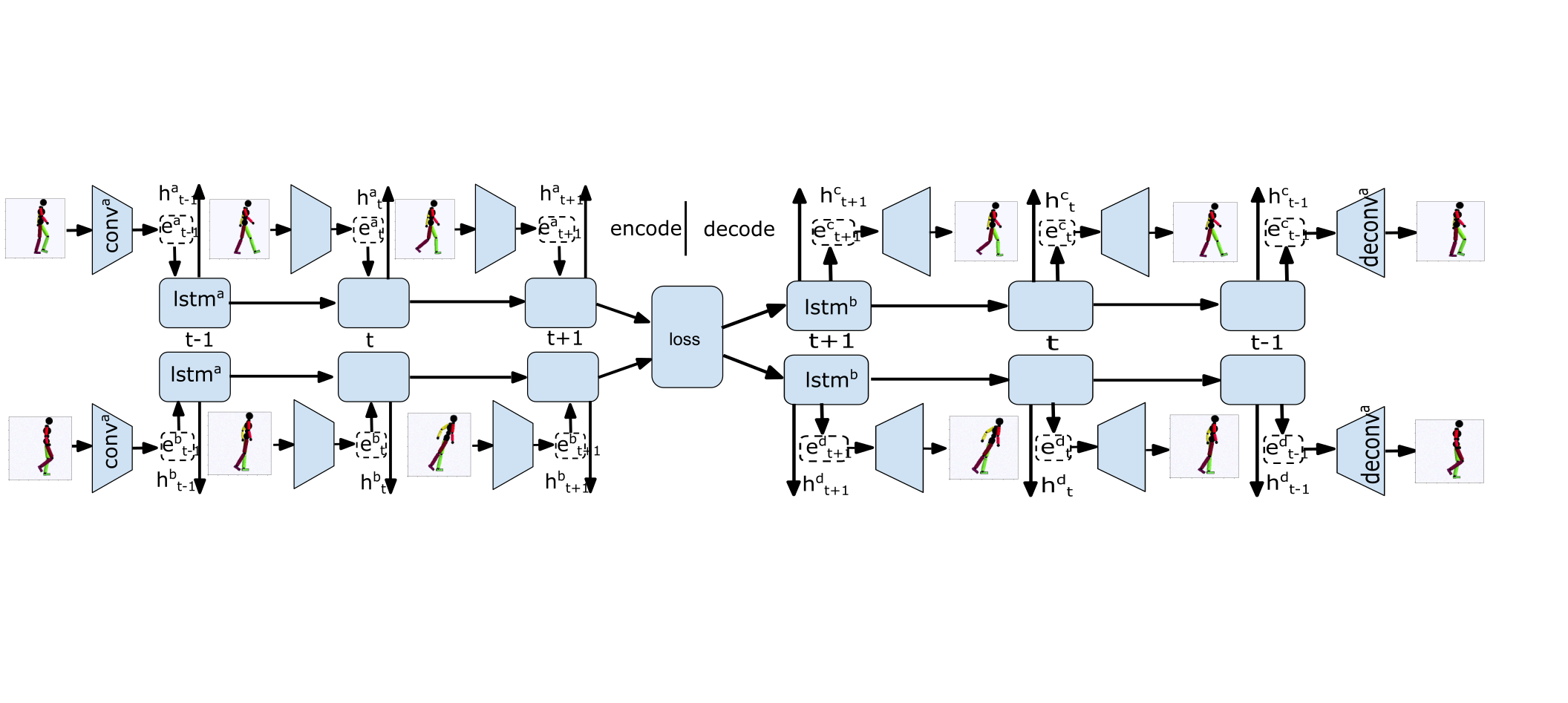
Siamese network
To learn these distances, we train a recurrent Siamese network. We train this method with positive and negative examples. Where positive examples are similar or from the same class, and negative examples are known to be different or are from different classes. The model is trained to produce similar encodings when two videos or images are the same and different encodings otherwise. Additional data is included from other tasks to assist in training the siamese network.
Results
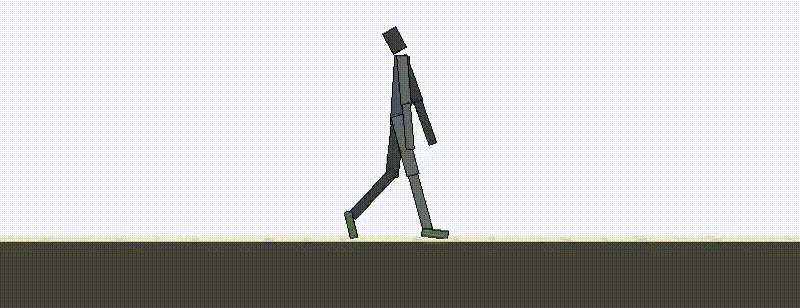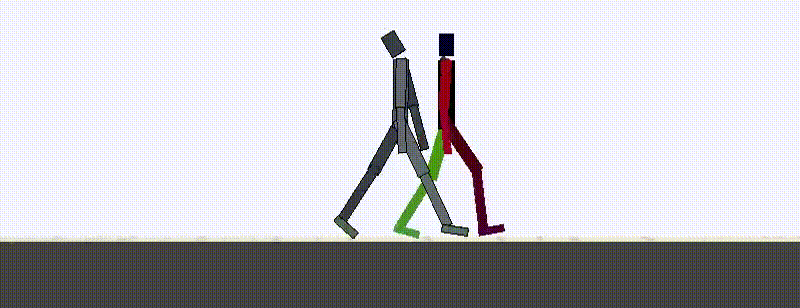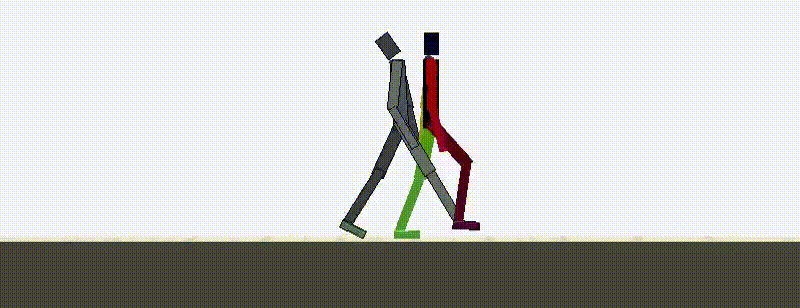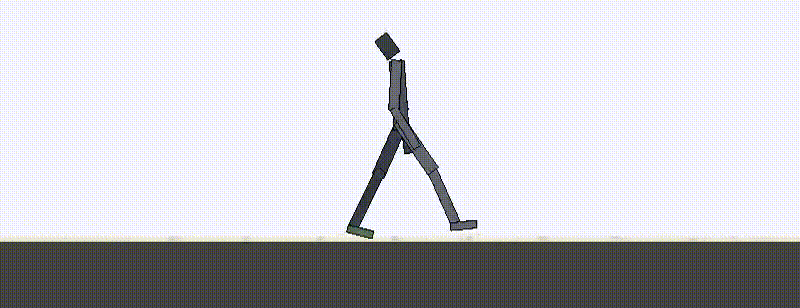
Using the spatial and temporal distance functions in combination, we can now train RL agents to match expert demonstrations from a single video example. The new temporal distances allow quick learning but have trouble achieving high-quality results without the addition of spatial rewards.

The addition of these new rewards using temporal distances (along with some additional insights) has enabled imitation learning of 3D motion imitation given only a single video demonstration. While these are the first results of its type, additional quality might be gained from multi-view video data or other multi-task data.
