Accueil

|
Je suis professeur adjoint à l'Université de Montréal, membre académique principal du Mila - Institut québécois de l'intelligence artificielle, titulaire de la Chaire d'IA Canada CIFAR, et co-directeur du Laboratoire de Robotique et d'IA Incarnée (REAL).
J'ai été chercheur post-doctoral au sein de la Recherche en Intelligence Artificielle de Berkeley (BAIR), travaillant avec Sergey Levine.
Mes recherches passées et actuelles sont axées sur la résolution de problèmes de prise de décision séquentielle pour les systèmes d'apprentissage autonome du monde réel (robots).
Plus précisément, mes recherches ont couvert les domaines de l'apprentissage par renforcement, continu, méta, hiérarchique et la collaboration homme-robot.
Dans le cadre de mon travail, j'ai publié dans les principales disciplines de la robotique, de l'apprentissage automatique et de l'animation informatique.
Actuellement, j'enseigne un cours sur l'apprentissage des robots à l'Université de Montréal et au Mila, qui couvre les recherches les plus récentes sur les techniques d'apprentissage automatique pour la création de robots généralistes.
Pour une biographie plus formelle, cliquez ici. |
Je soutiens Slow Science.
Nouvelles
-
(juillet 2026) Nouvel article de position accepté à ICML 2026 sur les risques de collusion entre agents de raisonnement IA, qui justifient des exigences de certification pour la prise de décisions de marché!
-
(janvier 2026) Trois nouveaux articles acceptés à ICLR 2025 sur l’exploration efficace avec apprentissage contrastif, des représentations auto-prédictives pour la généralisation combinatoire, et l’utilisation des LLM pour générer des fonctions de récompense structurées!
-
(mai 2025) Deux nouveaux articles acceptés à ICML 2025 sur Outsourced diffusion models et Continual RL!
-
(janvier 2025) Trois nouveaux articles acceptés à ICLR 2025 sur l'apprentissage par imitation efficace, l'exploration pour les GFN, et l'apprentissage par renforcement en temps réel!
-
(novembre 2024) Trois nouveaux articles acceptés à NeurIPS 2024 sur l’inverse safe RL, la convergence et la mise à l’échelle des algorithmes deepRL, et l’amortissement de l’inférence intraitable!
-
(août 2024) La première <a href=« https://rl-conference.cc/ »>Conférence sur l’apprentissage par renforcement</a> a été un véritable succès!
-
(juin 2024) New paper accepted to RSS 2024 on Making more diverse data sets for improving generalist robot policies!
-
(mai 2024) Best paper award at ICLR to ICLR 2024 on VLMs for robotics!
-
(janvier 2024) Five new papers accepted to ICLR 2024 on efficient exploration, generalization in sequence planning for supervised learning, Intelligent Switching for Reset-Free RL, Using LLMs and RL for drug discovery, and Latent diffusion for OfflineRL!
-
(juin 2022) q
-
(septembre 2021) q
-
(avril 2021) q
Research Talk (2023)
Recent Research Talk (2023)
Travaux Récents
Apprentissage par renforcement autonome en conditions réelles
|
Nous étudions comment les robots peuvent apprendre de manière autonome des compétences nécessitant à la fois la navigation et la préhension. Bien que l'apprentissage par renforcement permette en principe l'apprentissage automatisé des compétences robotiques, dans la pratique, l'apprentissage par renforcement dans le monde réel est complexe et nécessite souvent une instrumentation et une supervision importantes. Notre objectif est de concevoir un système d'apprentissage par renforcement robotique pour apprendre la navigation et la manipulation ensemble, de manière autonome et sans intervention humaine, permettant un apprentissage continu dans des conditions réalistes. Notre système proposé, ReLMM, peut apprendre en continu sur une plateforme du monde réel sans instrumentation environnementale, sans intervention humaine et sans accès à des informations privilégiées, telles que des cartes, des positions d'objets ou une vue globale de l'environnement. Notre méthode utilise une politique modularisée avec des composants pour la manipulation et la navigation, où l'incertitude de la politique de manipulation guide l'exploration pour le contrôleur de navigation, et le module de manipulation fournit des récompenses pour la navigation. Nous évaluons notre méthode sur une tâche de nettoyage de pièce, où le robot doit se déplacer et ramasser des objets dispersés sur le sol. Après une phase d'entraînement de curriculum de préhension, ReLMM peut apprendre la navigation et la préhension ensemble de manière entièrement automatique, en environ 40 heures d'entraînement autonome en conditions réelles. |
Généralisation entre robots par inférence de la morphologie
|
L'approche prototypique de l'apprentissage par renforcement consiste à former des politiques adaptées à un agent particulier à partir de zéro pour chaque nouvelle morphologie. Les travaux récents visent à éliminer la rétroaction des politiques en examinant si une politique agnostique à la morphologie, formée sur un ensemble diversifié d'agents ayant des objectifs de tâche similaires, peut être transférée à de nouveaux agents ayant des morphologies inconnues sans rétroformation. Il s'agit d'un problème complexe qui a nécessité que les approches précédentes utilisent des descriptions de la morphologie du nouvel agent préalablement conçues. Au lieu de concevoir manuellement cette description, nous proposons une méthode basée sur les données qui apprend une représentation de la morphologie directement à partir de l'objectif de l'apprentissage par renforcement. Notre approche est le premier algorithme d'apprentissage par renforcement capable de former une politique capable de se généraliser à de nouvelles morphologies d'agent sans nécessiter une description préalable de la morphologie de l'agent. Nous évaluons notre approche sur la référence standard pour le contrôle agnostique de l'agent et améliorons l'état actuel de l'art en généralisation sans formation préalable à de nouveaux agents. Importamment, notre méthode atteint de bonnes performances sans description explicite de la morphologie. |
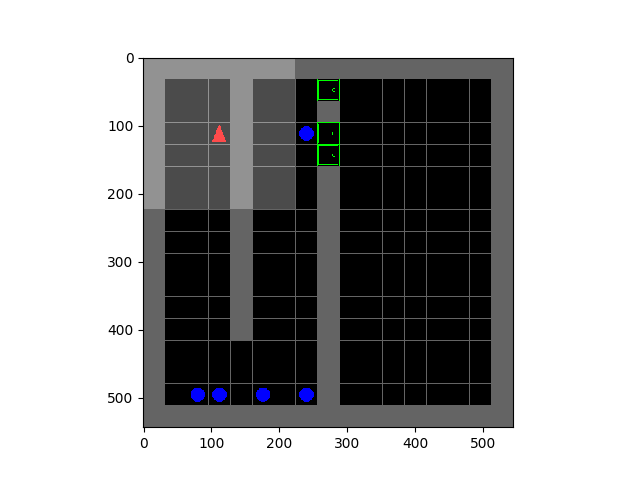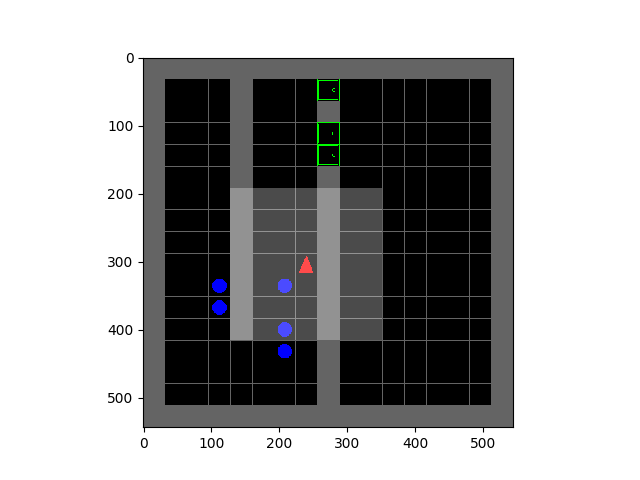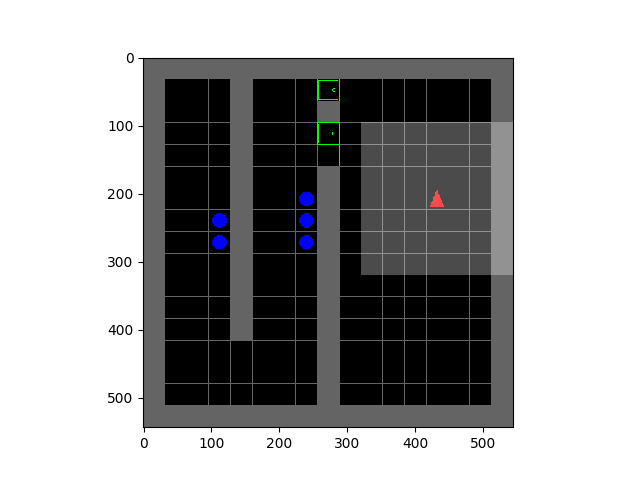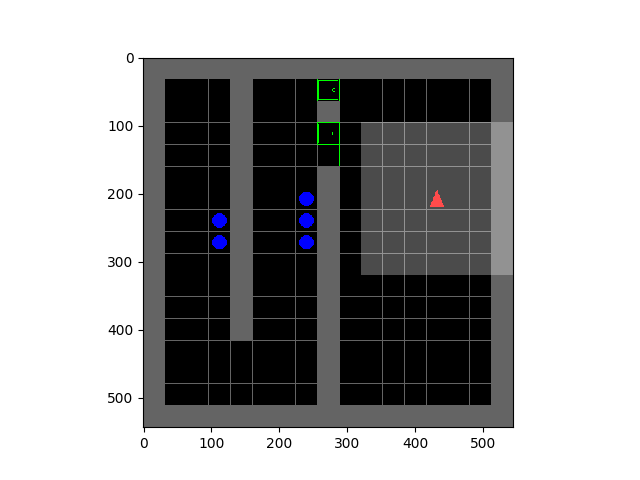
Minimisation de l'entropie pour des comportements émergents
|
Tous les organismes vivants définissent des niches environnementales dans lesquelles ils peuvent maintenir une prédictibilité relative au milieu de l'entropie croissante qui les entoure [schneider1994, friston2009]. Les êtres humains, par exemple, font de grands efforts pour se protéger de la surprise : nous nous regroupons par millions pour construire des villes avec des maisons, fournissant de l'eau, de la nourriture, du gaz et de l'électricité pour contrôler la détérioration de nos corps et de nos espaces de vie face à la chaleur et au froid, au vent et à la tempête. Le besoin de découvrir et de maintenir de tels équilibres sans surprise a suscité beaucoup d'ingéniosité et d'habileté chez les organismes dans des habitats naturels très divers. Motivés par cela, nous nous demandons si le désir de préserver l'ordre au milieu du chaos pourrait guider l'acquisition automatique de comportements utiles chez les agents artificiels. |