Behavioral Cloning Breaks in Predictable Ways (and What Helps)
Behavioral cloning performs well when predictions stay near the expert distribution, but small rollout errors compound and push policies into unseen states. In multi-modal expert data, standard MSE objectives tend to average distinct behaviors, producing trajectories that match neither mode. Action chunking improves short-horizon consistency, and deeper models can better fit demonstrations, yet neither fully resolves distribution shift. These experiments show why BC is a strong baseline but not a complete solution for long-horizon, stochastic control.
Behavioral Cloning (BC) is one of the simplest ways to learn control policies: train a model to imitate expert actions from state-action pairs. It can work surprisingly well in short horizons—and fail surprisingly fast in longer rollouts.
This post walks through a compact set of experiments showing where BC fails, why those failures happen, and what partial fixes look like. These Failures are connection to the error bounds from the Dagger paper which are \(J(\hat{\pi}) \leq J(\pi^*) + T^2\epsilon\) for normal BC. Where \(T\) is the number of time steps for panning and \(\epsilon\) is the average error of the model.
This post is based on this notebook which was intentionally designed to make these failure modes visible rather than hidden by over-tuning. In practice, changing seeds, model width/depth, or rollout length can make outcomes look better or worse in a single run, but the same structural issues keep reappearing: distribution shift and mode ambiguity.
How to Read the Notebook and Plots
The notebook includes a few practical notes that matter when interpreting the results:
- The expert path in Part 1 is intentionally not a trivial straight line. A too-simple expert can hide BC failure modes.
- Seed choice noticeably changes outcomes, especially in the stochastic sections. A single “good-looking” run should not be treated as proof of robustness.
- Increasing optimization steps can improve fit but can also make long-horizon drift easier to expose.
- The later sections are structured as self-contained training/evaluation blocks so each result can be read independently as an experiment.
Treat each figure as an execution-time behavior check, not just a training-loss report.
Why BC Is Harder Than It Looks
Two issues dominate in practice:
-
Compounding error (distribution shift): The model is trained on expert states, but evaluated on its own visited states. Small action errors push the agent off-manifold, and those errors accumulate over time.
-
Stochastic experts (multi-modal behavior): If experts sometimes choose different valid actions in the same context, a standard MSE objective tends to average those modes. The average can be physically invalid or unsafe.
In this post, these are illustrated with low-dimensional trajectory plots so the pathology is easy to see: one failure looks like growing drift away from a reference path, and the other looks like “going down the middle” between two valid expert modes.
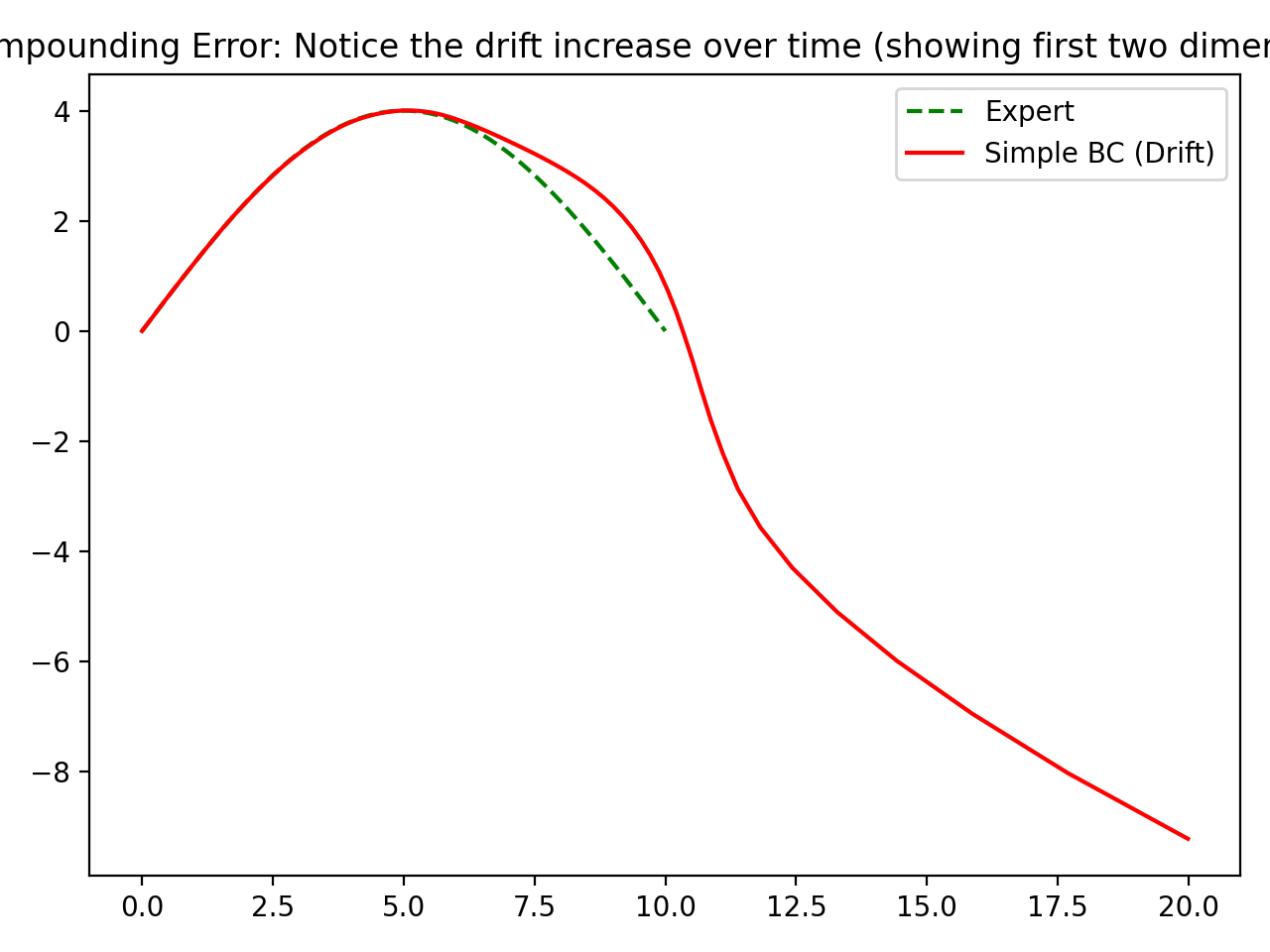
Experiment 1: Regular BC and Drift
I trained a simple feedforward BC model on a smooth expert trajectory, then rolled it out autoregressively.
The key detail here is that training and testing are mismatched by construction: during training, the model sees expert states; during rollout, it must consume its own predicted next states. That mismatch is small at the beginning and larger later in time.
The accompanying notebook explicitly calls out that you may need to run this setup multiple times or with longer training to surface stronger divergence. That is not a bug in the demonstration; it reflects instability in rollout behavior under slightly different training outcomes.
Observed behavior:
- Early trajectory tracking is reasonable.
- Drift grows over time.
- Final trajectory diverges significantly from the expert.
Interpretation: This is classic compounding error. One-step prediction quality does not guarantee long-horizon policy stability.
In other words, BC can look strong under teacher-forced metrics while still failing in closed-loop execution, which is what actually matters for control.
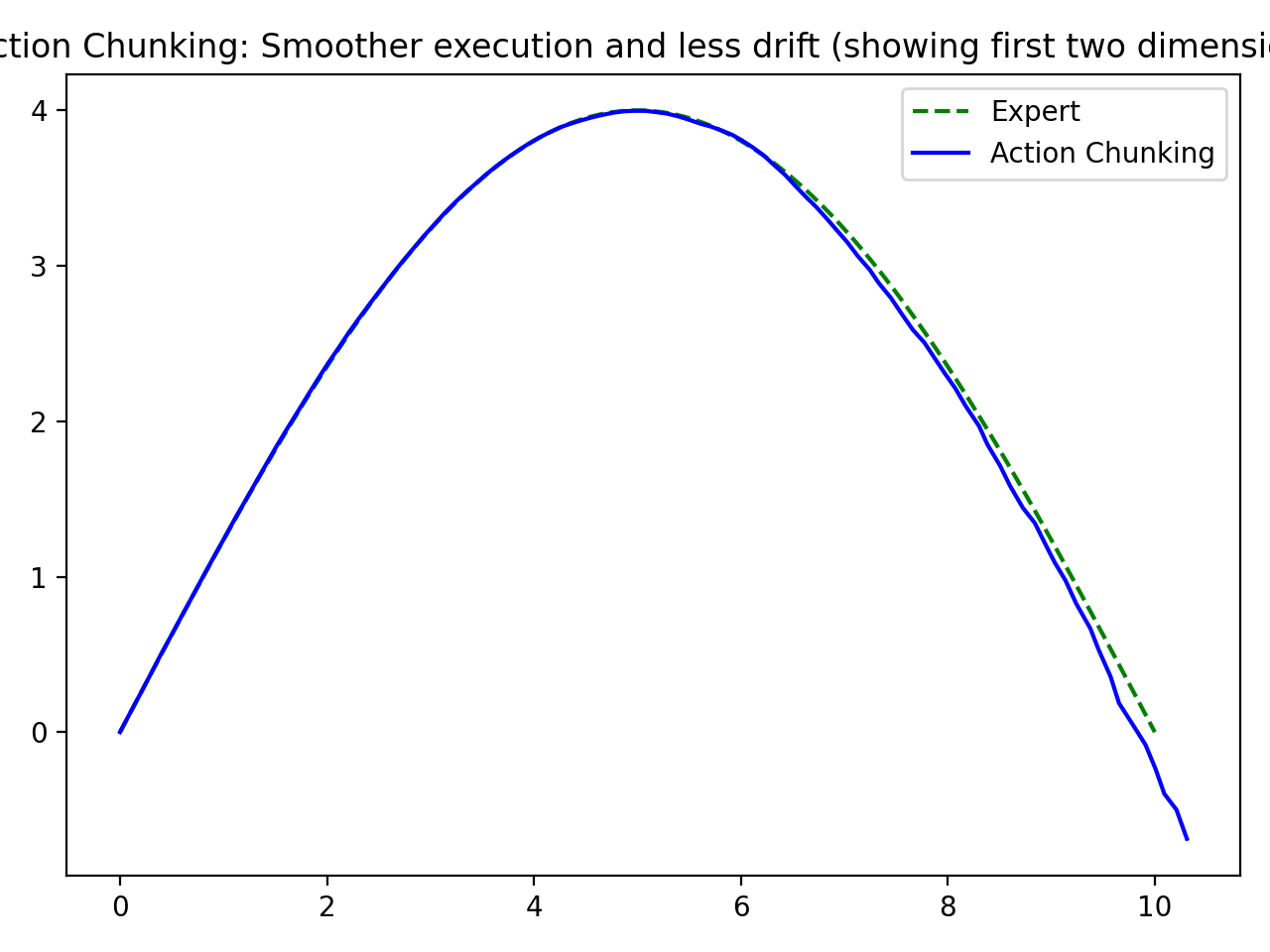
Experiment 2: Action Chunking
Instead of predicting a single next action, the model predicts a short sequence of future actions (an action chunk).
This changes the learning target from purely reactive one-step correction to short-horizon intent. In the notebook, chunking is implemented with a sliding window of action targets and then unrolled at inference time.
Observed behavior:
- Rollouts are smoother.
- Drift is reduced compared with single-step BC.
- Long-horizon mismatch still exists, but degradation is slower.
Interpretation: Chunking helps by enforcing short-horizon consistency and reducing per-step feedback sensitivity.
It is best viewed as a mitigation, not a cure: the agent can still leave the expert manifold over long horizons, just less abruptly.
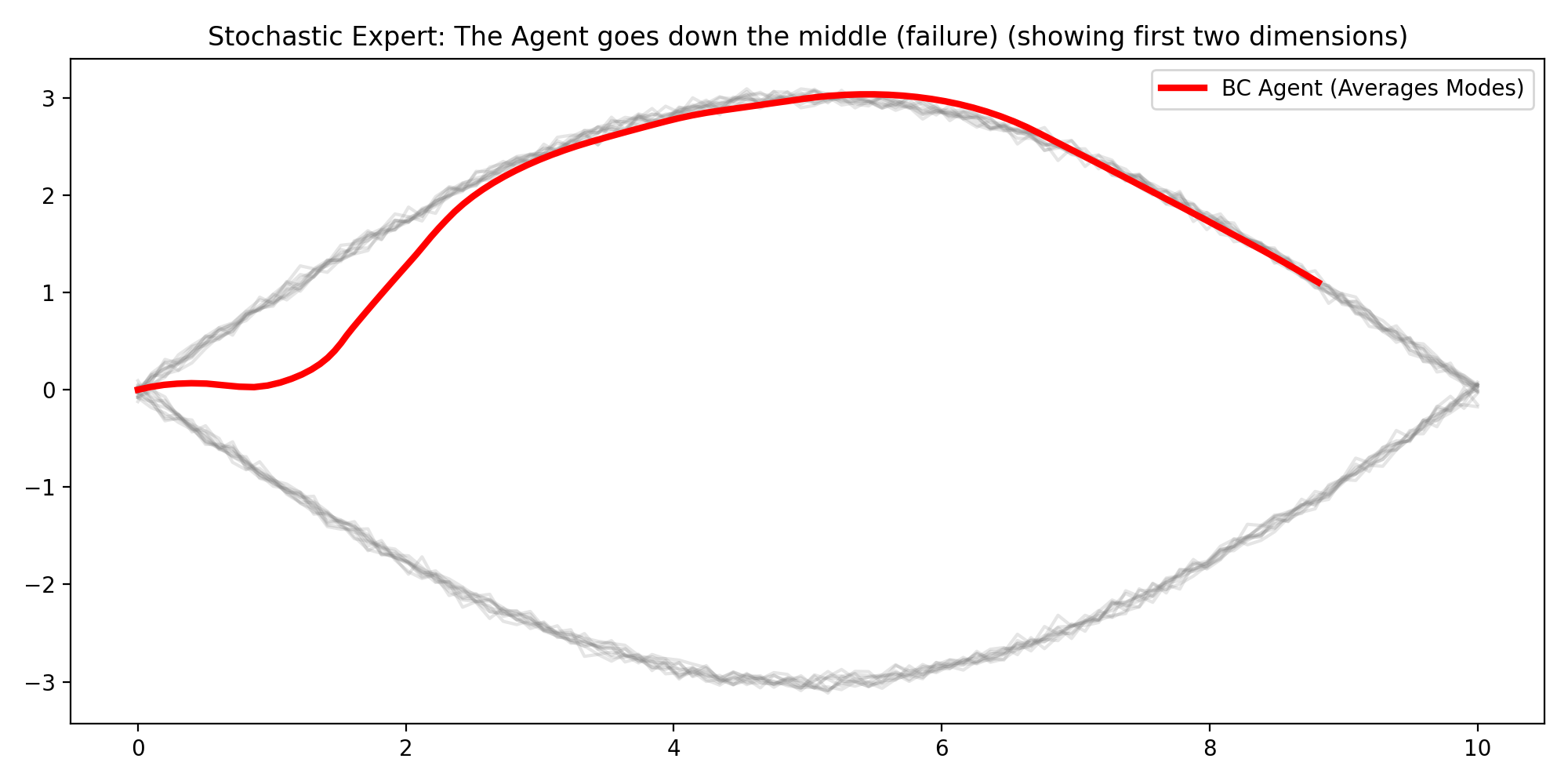
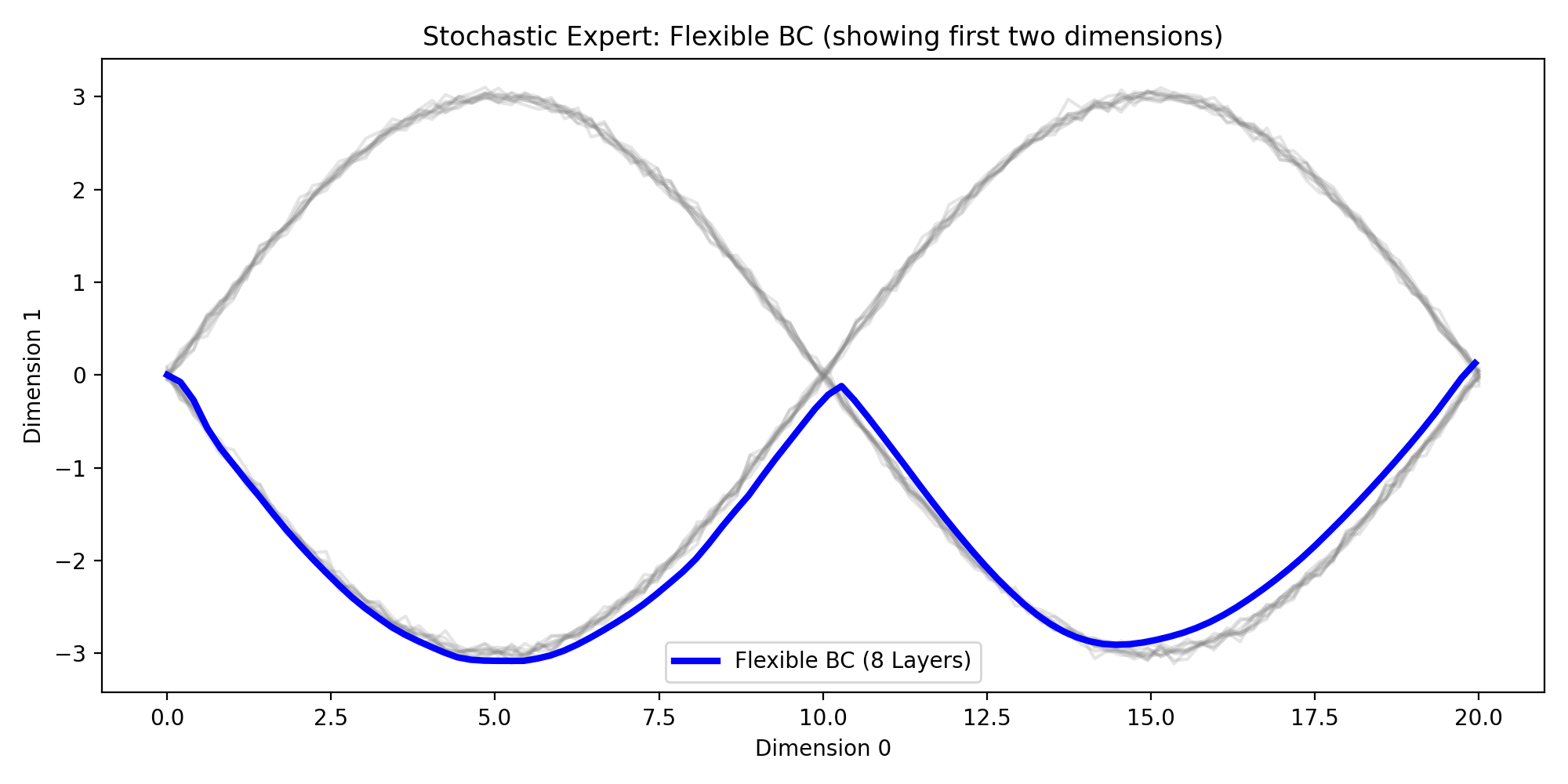
Experiment 3: Stochastic Expert Failure Mode
I generated multi-modal expert demonstrations (e.g., trajectories that go “high” or “low”) and trained standard BC.
This setup highlights a second, different BC limitation: ambiguity in the target itself. If the same or similar states map to multiple valid actions in the data, plain regression losses encourage averaging across those choices.
The behaviour we observe, is a combination of mode averaging new [0,0] and then mode seeking after x > 1 is exactly why the result is described as potentially disastrous in robotics: averaging between valid modes can produce behavior that matches neither intent nor safe execution.
Observed behavior:
- The learned policy often tracks the middle region between modes.
- The rollout is not representative of either expert mode.
Interpretation: MSE-trained BC collapses distinct behaviors into an average. This is a known failure mode for ambiguous expert data.
In robotics terms, averaging can produce actions that are locally “reasonable” under loss minimization but globally poor under task dynamics.
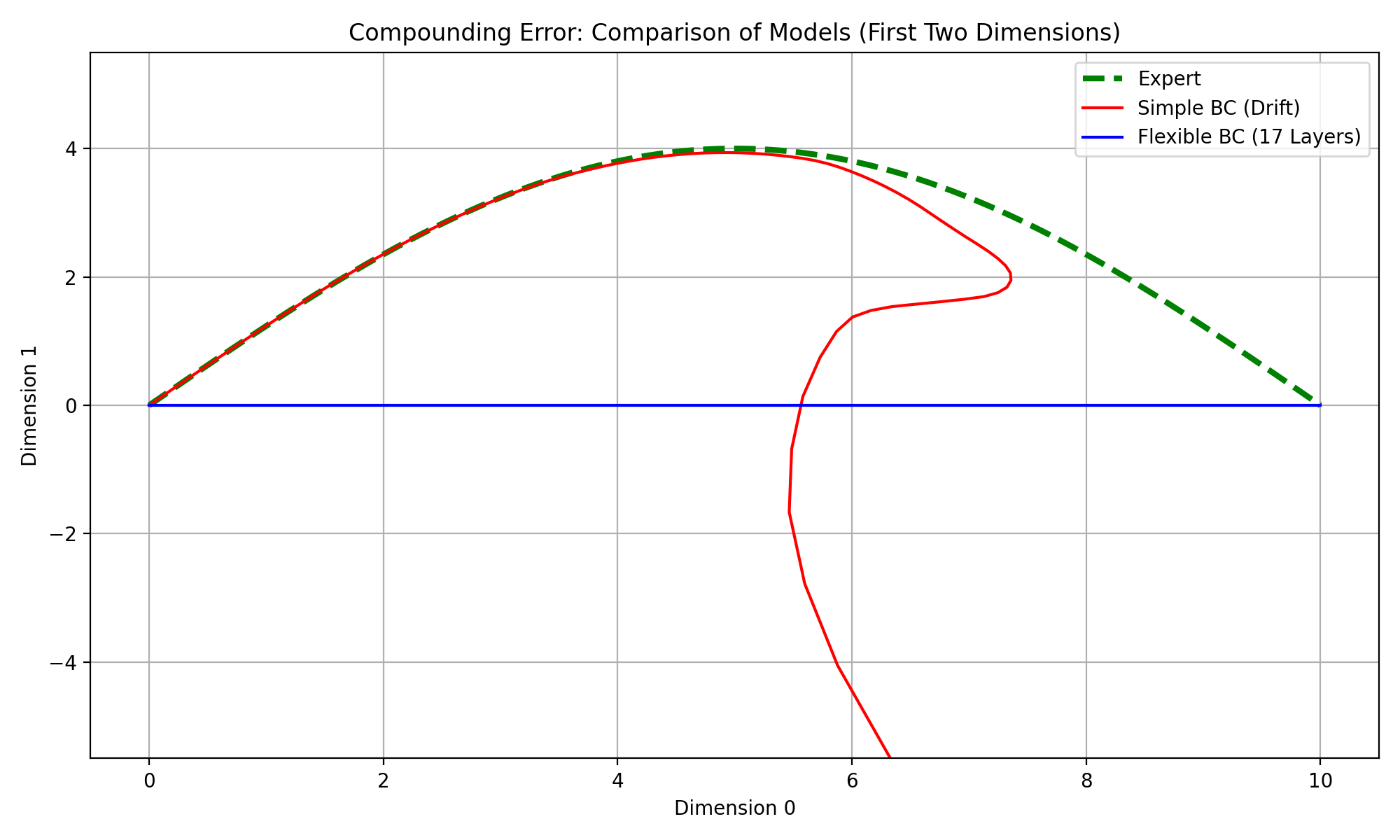
Experiment 4: Increasing Model Depth
I compared a basic BC network against a deeper, wider variant.
The notebook discussion notes an important nuance: more capacity can improve in-distribution fit and initially cleaner trajectories, but it can also become more sensitive to small errors if not well regularized. There is an odd behavour where if 16 layers are used the model does a good job of mathcing the expert, but once a a 17th layer is added the model learns very little.
Observed behavior:
- Larger models can fit expert actions better in-distribution.
- In some runs, deeper models track expert trajectories longer before deviating.
- Distribution-shift failures still appear over longer rollouts.
Interpretation: Model capacity improves approximation but does not solve BC’s core mismatch between training and deployment distributions.
This is why architecture changes alone usually plateau: they reduce error constants but do not remove the recursive rollout feedback loop that creates compounding drift. In addition, training more complex models mean deadling with more complex training dynamics, which complicates the understanding from parts 1-3. Reducing the error such that \(\epsilon\) is not we evenly distributed across the state and action space.
Experiment 5: Deeper Model on Stochastic Experts
I trained the deeper BC model on the same multi-modal data.
Relative to the shallow model, the deeper network can represent richer patterns and may appear to commit to one mode for longer segments. But because mode selection is still implicit, behavior can remain inconsistent across runs and along long rollouts.
The notebook text also emphasizes the setup logic here: regenerate stochastic data, train a configurable flexible model in a self-contained block, then evaluate rollout behavior against the gray expert-mode trajectories. That structure is useful because it isolates whether improved behavior comes from architecture capacity versus accidental state carry-over between cells.
Interpretation: Higher capacity helps represent richer behavior, but without explicit mode modeling or conditioning, stochasticity remains a hard problem.
This mirrors the notebook’s final discussion: depth/width help representation, yet robust multi-modal imitation usually needs objectives or architectures that explicitly model mode uncertainty.
The two concrete failure pressures in this section remain the same as described in the notebook discussion:
- Mode ambiguity: without explicit conditioning or latent mode variables, the policy may switch or average.
- Compounding error: even when mode capture improves, rollout drift still accumulates over long horizons.
Key Takeaways
- BC is a strong baseline, but brittle in long-horizon closed-loop control.
- Action chunking is a practical improvement for rollout stability.
- More layers/width can improve fit but do not remove distribution shift.
- Multi-modal experts expose a fundamental weakness of MSE imitation.
The pattern is consistent, better function approximation improves short-term behavior, but stable long-horizon imitation needs mechanisms that address data distribution mismatch and mode ambiguity directly.
Where to Go Next
If you want BC that behaves robustly in stochastic or long-horizon tasks, likely next steps are:
- Conditional policies to disambiguate modes.
- Iterative data aggregation (e.g., DAgger-style corrections).
- Sequence models / latent-variable policies to represent multi-modal action distributions.
- Uncertainty-aware or generative imitation objectives instead of plain MSE.